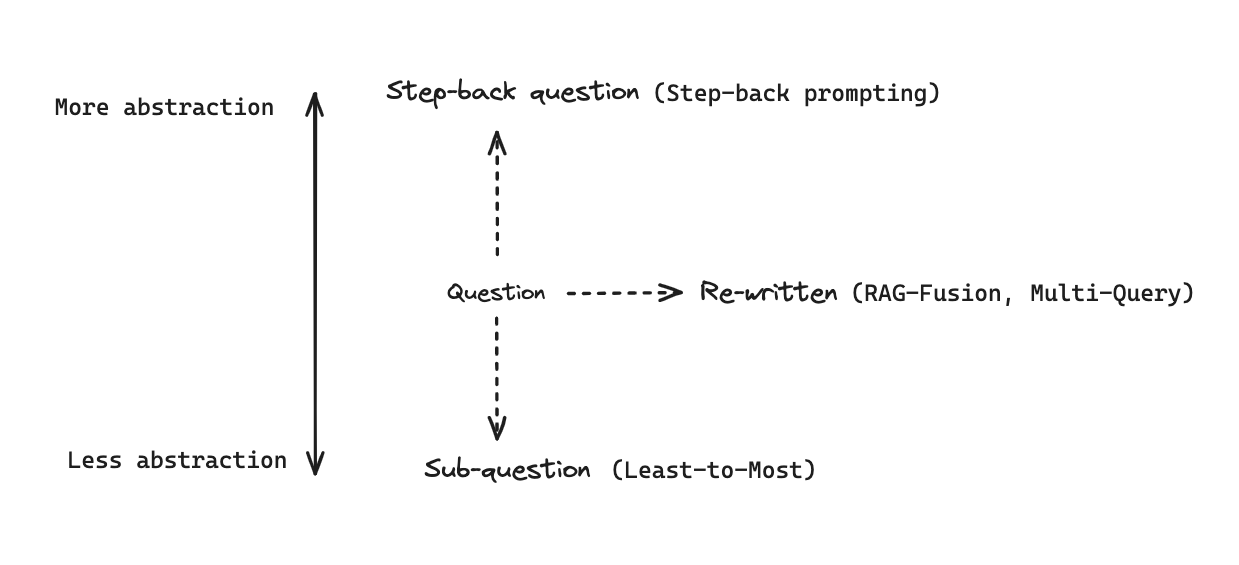
graph LR
subgraph "演进路径"
A[全局Card Table] --> B[并发Card Table]
B --> C[Remembered Set]
C --> D[染色指针]
end
subgraph "技术特点"
A1[简单] --> A2[串行]
B1[原子操作] --> B2[预清理]
C1[Region级] --> C2[精细化管理]
D1[无额外结构] --> D2[指针编码]
end
style A fill:#add8e6
style B fill:#ffeb3b
style C fill:#90ee90
style D fill:#ff6b6b
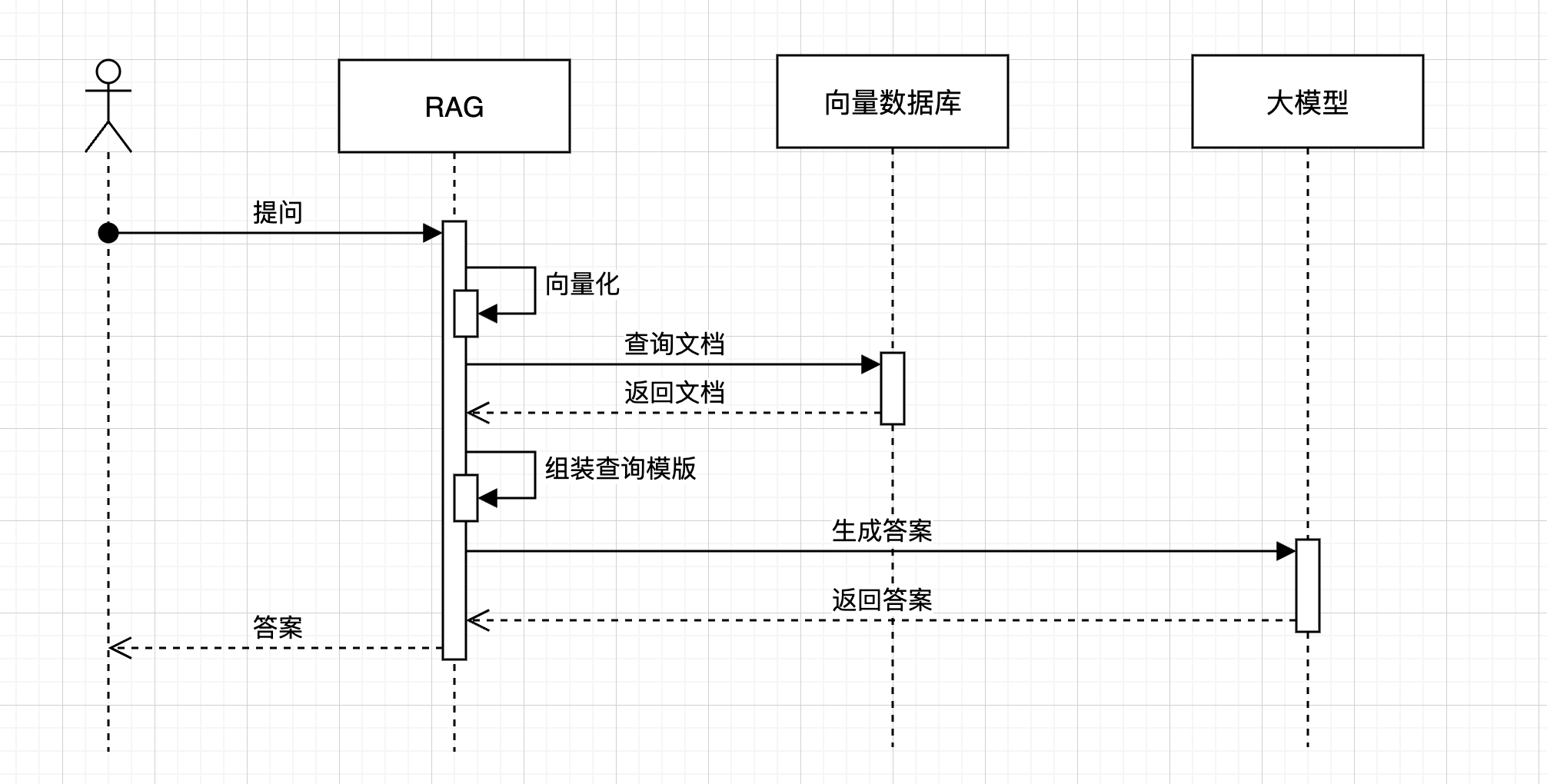
四、各种GC的具体实现
1. Parallel GC中的Card Table
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
特点: - 传统分代模型 - 单个Card Table - 简单的脏卡标记
Card Table布局: [Young Gen Cards] [Old Gen Cards] 0-1024 1024-2048
graph TD
subgraph "GC Roots"
GR1[Thread Stack]
GR2[Static Fields]
GR3[JNI References]
end
subgraph "对象引用链"
A[Object A] --> B[Object B]
A --> C[Object C]
B --> D[Object D]
C --> E[Object E]
F[Unreachable Object]
end
GR1 --> A
GR2 --> A
GR3 --> C
style F fill:#ffcccc
style A fill:#ccffcc
style B fill:#ccffcc
style C fill:#ccffcc
style D fill:#ccffcc
style E fill:#ccffcc
分析步骤:
枚举GC Roots:找到所有GC Roots对象
递归遍历:从GC Roots开始递归遍历引用链
标记存活对象:将所有可达对象标记为存活
回收垃圾对象:回收未被标记的对象
GC Roots枚举的实现
1. 准确式GC与保守式GC
准确式GC(Exact GC):
虚拟机明确知道内存中哪些位置是引用
通过OopMap数据结构记录对象引用的位置
HotSpot虚拟机采用准确式GC
保守式GC(Conservative GC):
不能准确区分引用和非引用数据
通过启发式算法判断是否为引用
可能存在”假引用”问题
2. 安全点(Safepoint)
由于GC Roots枚举需要在一个能看到一致内存快照的点进行,JVM引入了安全点机制:
1 2 3 4 5 6
publicvoidlongRunningMethod() { for (inti=0; i < 1000000; i++) { // 方法调用、循环跳转、异常跳转等位置可以设置安全点 doSomething(); // 这里是安全点 } }
sequenceDiagram
participant GC as GC线程
participant App as 应用线程
participant Black as 黑色对象A
participant White as 白色对象B
Note over GC,App: 对象消失问题场景
GC->>Black: 标记对象A为黑色
GC->>White: 对象B仍为白色
Note over GC,App: 此时A引用B,B应该被标记
App->>Black: A.field = null (断开引用)
GC->>GC: 完成标记,回收白色对象
Note over GC: 错误:B被回收,但可能还有其他引用
graph TD
subgraph "互联网应用爆发"
A[电商平台] --> B[在线支付]
B --> C[社交媒体]
C --> D[实时游戏]
end
subgraph "用户体验要求"
E[响应时间<100ms] --> F[页面流畅度>60fps]
F --> G[零容忍长时间卡顿]
end
D --> G
style A fill:#ffebcd
style B fill:#ffebcd
style C fill:#ffebcd
style D fill:#ffebcd
style E fill:#add8e6
style F fill:#add8e6
style G fill:#ff6b6b
用户体验影响链:
graph LR
U[用户点击购买] --> GC[GC停顿3秒]
GC --> PAGE[页面无响应]
PAGE --> BAD[用户体验差]
BAD --> LOSE[用户流失/订单损失]
style GC fill:#ff6b6b
style LOSE fill:#ff6b6b
graph TD
subgraph "CMS并发架构"
A[应用线程] <-->|并发执行| B[GC线程]
B --> C[并发标记]
B --> D[并发清除]
A --> E[短暂停顿点]
E --> F[初始标记]
E --> G[重新标记]
end
subgraph "传统GC架构"
H[应用线程] -.->|完全停止| I[GC线程]
I --> J[串行标记]
I --> K[串行清除]
end
style A fill:#90ee90
style B fill:#90ee90
style C fill:#90ee90
style D fill:#90ee90
style H fill:#ffcccb
style I fill:#ffcccb
技术挑战与解决方案:
graph LR
subgraph "挑战"
T1[线程协调复杂]
T2[内存动态变化]
T3[CPU资源竞争]
end
subgraph "解决方案"
S1[写屏障技术]
S2[三色标记法]
S3[自适应调度]
end
T1 --> S1
T2 --> S2
T3 --> S3
style T1 fill:#ffcccb
style T2 fill:#ffcccb
style T3 fill:#ffcccb
style S1 fill:#90ee90
style S2 fill:#90ee90
style S3 fill:#90ee90
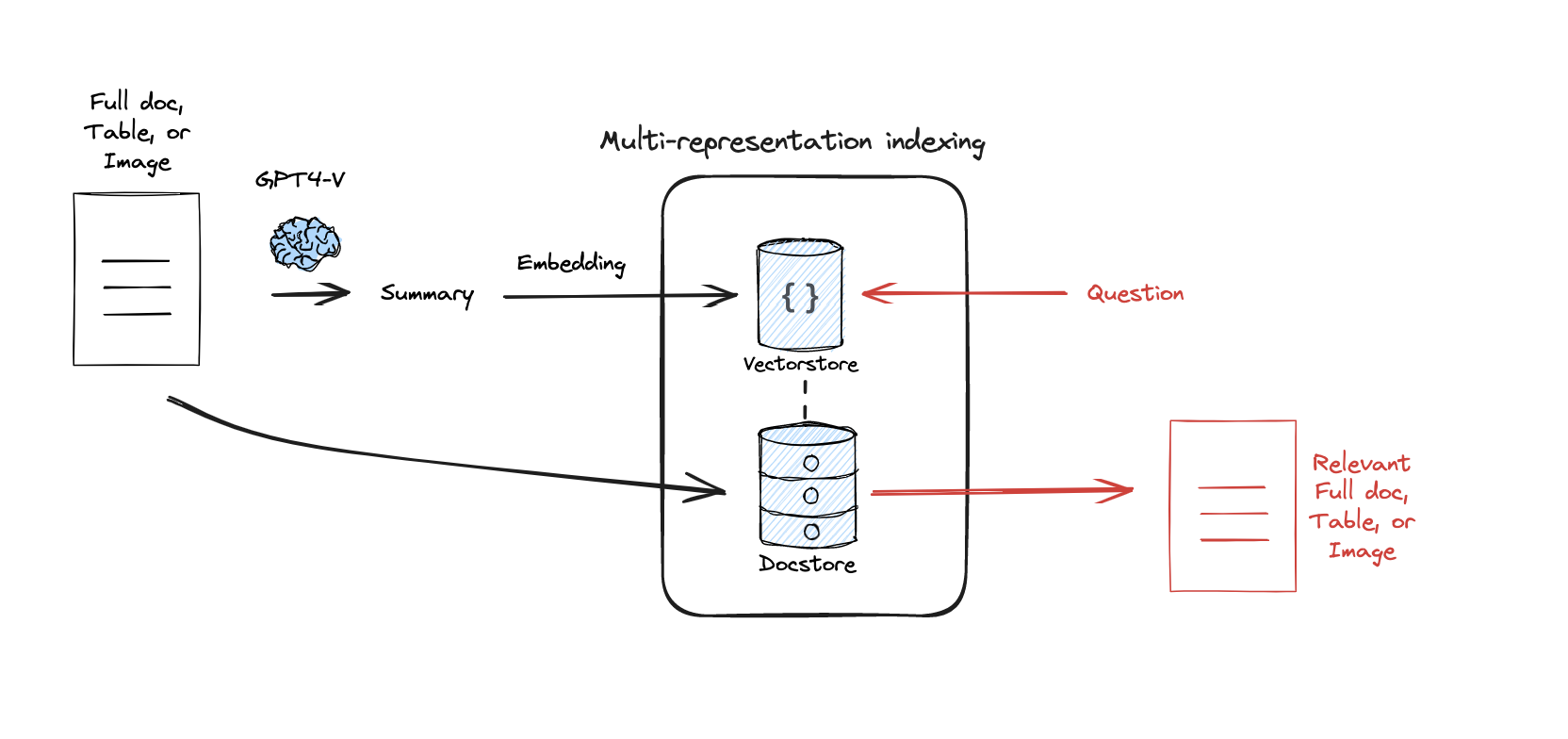
import uuid from langchain_core.documents import Document from langchain_openai import OpenAIEmbeddings from langchain_community.vectorstores import Chroma from langchain.storage import InMemoryByteStore from langchain.retrievers.multi_vector import MultiVectorRetriever
# 假设我们有两个原始文档 raw_docs = [ "LangChain is a framework for developing applications powered by language models.", "Chroma is a vector database used for similarity search over embeddings." ]
# 为每个原始文档生成多个摘要(手动模拟,也可以用 LLM 自动生成) summaries = [ ["LangChain is a framework for LLM apps.", "It helps chain language model calls."], ["Chroma is a vector store.", "It supports similarity search for embeddings."] ]
# 给每个原始文档生成唯一 ID doc_ids = [str(uuid.uuid4()) for _ in raw_docs]
# 准备子文档(用于嵌入、向量检索) summary_docs = [] for i, summary_list inenumerate(summaries): for s in summary_list: summary_docs.append(Document(page_content=s, metadata={"doc_id": doc_ids[i]}))
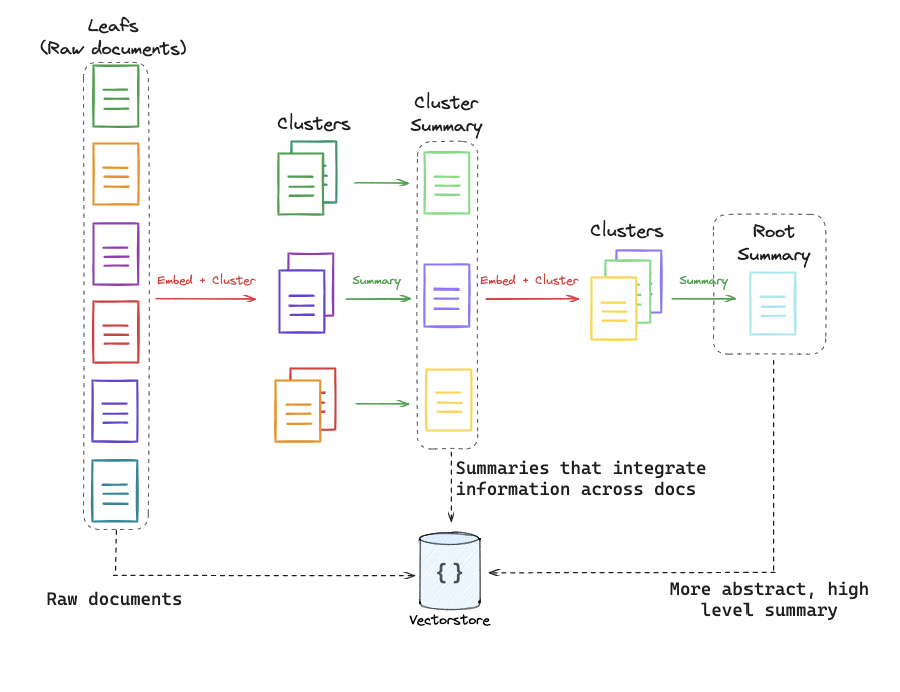
# 伪代码:chunk → title → embedding from langchain_core.documents import Document from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_openai import ChatOpenAI
# Data model classRouteQuery(BaseModel): """Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field( ..., description="Given a user question choose which datasource would be most relevant for answering their question", )
# LLM with function call llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) structured_llm = llm.with_structured_output(RouteQuery)
# Prompt system = """You are an expert at routing a user question to the appropriate data source. Based on the programming language the question is referring to, route it to the relevant data source."""
from langchain.utils.math import cosine_similarity from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnableLambda, RunnablePassthrough from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Two prompts physics_template = """You are a very smart physics professor. \ You are great at answering questions about physics in a concise and easy to understand manner. \ When you don't know the answer to a question you admit that you don't know. Here is a question: {query}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \ You are so good because you are able to break down hard problems into their component parts, \ answer the component parts, and then put them together to answer the broader question. Here is a question: {query}"""
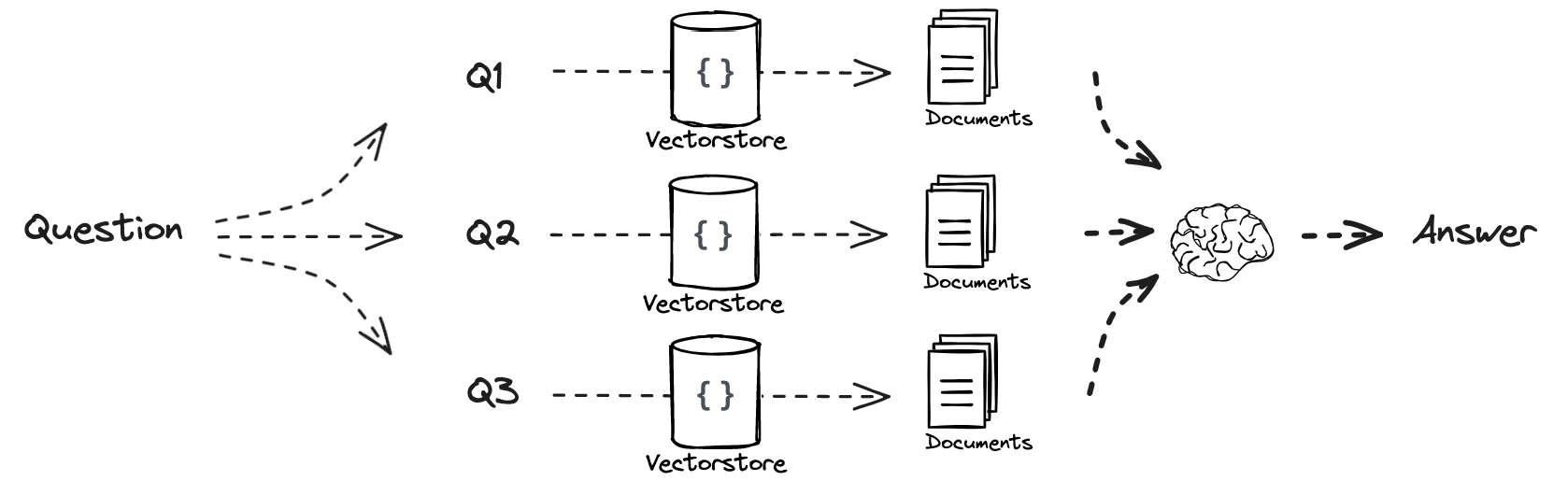
# Multi Query: Different Perspectives template = """You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""" prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI
defget_unique_union(documents: list[list]): """ Unique union of retrieved docs """ # Flatten list of lists, and convert each Document to string flattened_docs = [dumps(doc) for sublist in documents for doc in sublist] # Get unique documents unique_docs = list(set(flattened_docs)) # Return return [loads(doc) for doc in unique_docs]
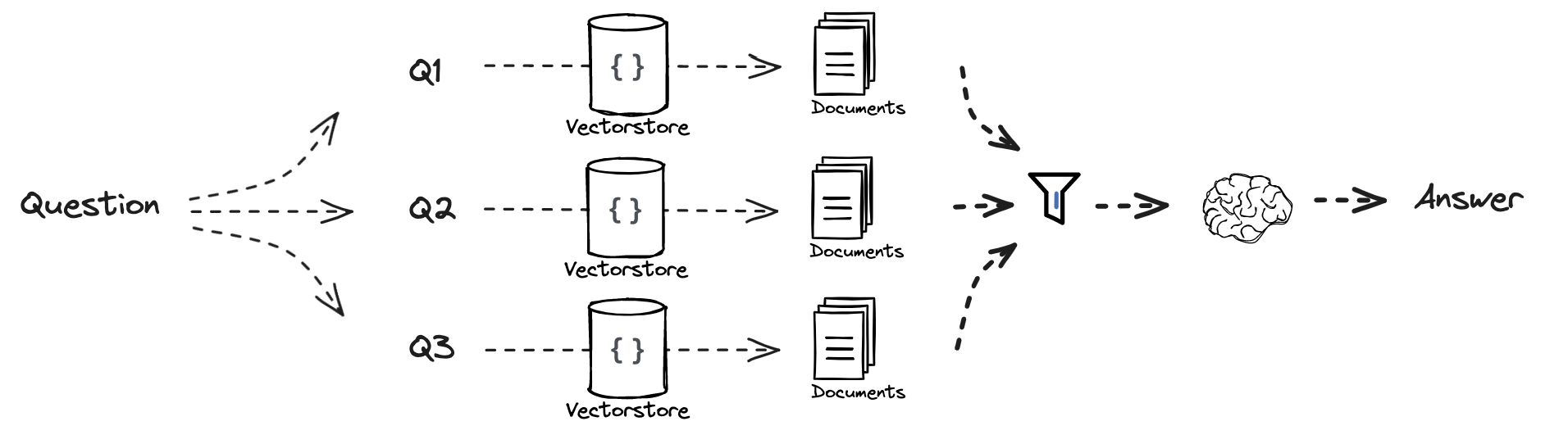
defreciprocal_rank_fusion(results: list[list], k=60): """ Reciprocal_rank_fusion that takes multiple lists of ranked documents and an optional parameter k used in the RRF formula """ # Initialize a dictionary to hold fused scores for each unique document fused_scores = {}
# Iterate through each list of ranked documents for docs in results: # Iterate through each document in the list, with its rank (position in the list) for rank, doc inenumerate(docs): # Convert the document to a string format to use as a key (assumes documents can be serialized to JSON) doc_str = dumps(doc) # If the document is not yet in the fused_scores dictionary, add it with an initial score of 0 if doc_str notin fused_scores: fused_scores[doc_str] = 0 # Retrieve the current score of the document, if any previous_score = fused_scores[doc_str] # Update the score of the document using the RRF formula: 1 / (rank + k) fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results reranked_results = [ (loads(doc), score) for doc, score insorted(fused_scores.items(), key=lambda x: x[1], reverse=True) ]
# Return the reranked results as a list of tuples, each containing the document and its fused score return reranked_results
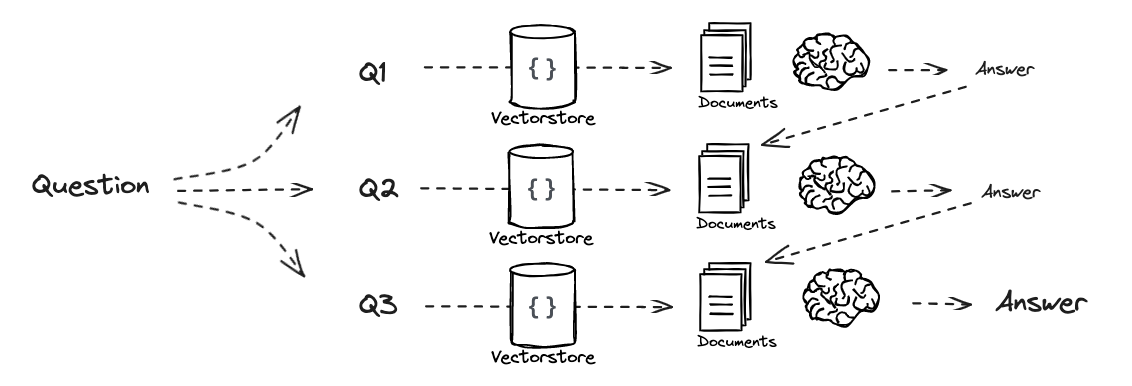
# Decomposition template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n Generate multiple search queries related to: {question} \n Output (3 queries):""" prompt_decomposition = ChatPromptTemplate.from_template(template) from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser
# Run question = "What are the main components of an LLM-powered autonomous agent system?" questions = generate_queries_decomposition.invoke({"question":question}) # Prompt template = """Here is the question you need to answer: \n --- \n {question} \n --- \n Here is any available background question + answer pairs: \n --- \n {q_a_pairs} \n --- \n Here is additional context relevant to the question: \n --- \n {context} \n --- \n Use the above context and any background question + answer pairs to answer the question: \n {question} """
decomposition_prompt = ChatPromptTemplate.from_template(template) from operator import itemgetter from langchain_core.output_parsers import StrOutputParser
defformat_qa_pair(question, answer): """Format Q and A pair""" formatted_string = "" formatted_string += f"Question: {question}\nAnswer: {answer}\n\n" return formatted_string.strip()
from langchain import hub from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI
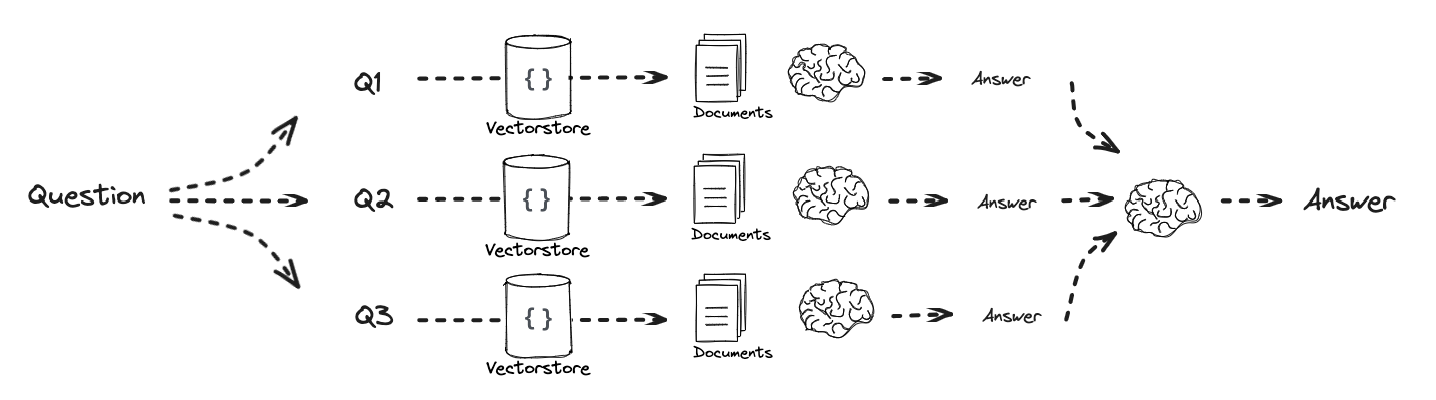
defretrieve_and_rag(question,prompt_rag,sub_question_generator_chain): """RAG on each sub-question""" # Use our decomposition / sub_questions = sub_question_generator_chain.invoke({"question":question}) # Initialize a list to hold RAG chain results rag_results = [] for sub_question in sub_questions: # Retrieve documents for each sub-question retrieved_docs = retriever.get_relevant_documents(sub_question) # Use retrieved documents and sub-question in RAG chain answer = (prompt_rag | llm | StrOutputParser()).invoke({"context": retrieved_docs, "question": sub_question}) rag_results.append(answer) return rag_results,sub_questions
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
defformat_qa_pairs(questions, answers): """Format Q and A pairs""" formatted_string = "" for i, (question, answer) inenumerate(zip(questions, answers), start=1): formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n" return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt template = """Here is a set of Q+A pairs: {context} Use these to synthesize an answer to the question: {question} """
# Few Shot Examples from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate examples = [ { "input": "Could the members of The Police perform lawful arrests?", "output": "what can the members of The Police do?", }, { "input": "Jan Sindel’s was born in what country?", "output": "what is Jan Sindel’s personal history?", }, ] # We now transform these to example messages example_prompt = ChatPromptTemplate.from_messages( [ ("human", "{input}"), ("ai", "{output}"), ] ) few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) prompt = ChatPromptTemplate.from_messages( [ ( "system", """You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""", ), # Few shot examples few_shot_prompt, # New question ("user", "{question}"), ] ) generate_queries_step_back = prompt | ChatOpenAI(temperature=0) | StrOutputParser() question = "What is task decomposition for LLM agents?" generate_queries_step_back.invoke({"question": question}) # Response prompt response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant. # {normal_context} # {step_back_context} # Original Question: {question} # Answer:""" response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = ( { # Retrieve context using the normal question "normal_context": RunnableLambda(lambda x: x["question"]) | retriever, # Retrieve context using the step-back question "step_back_context": generate_queries_step_back | retriever, # Pass on the question "question": lambda x: x["question"], } | response_prompt | ChatOpenAI(temperature=0) | StrOutputParser() )
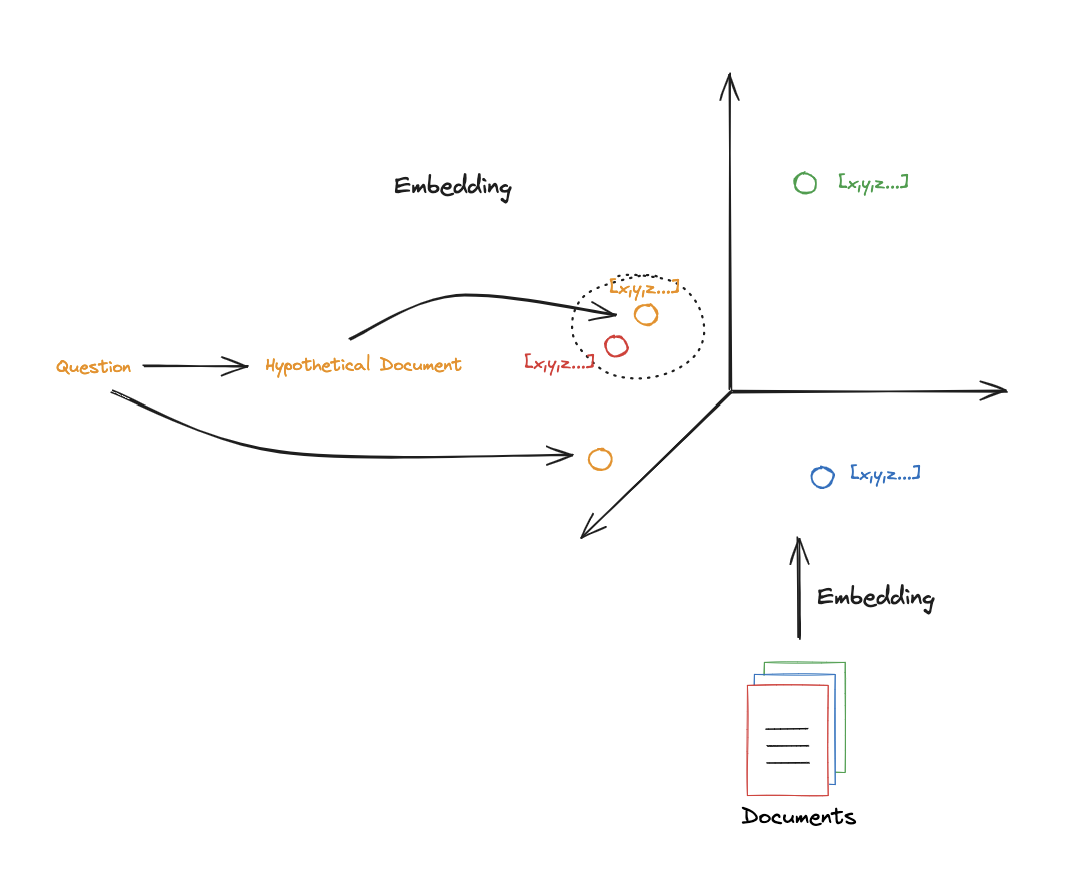
# Run question = "What is task decomposition for LLM agents?" generate_docs_for_retrieval.invoke({"question":question}) # Retrieve retrieval_chain = generate_docs_for_retrieval | retriever retireved_docs = retrieval_chain.invoke({"question":question}) retireved_docs # RAG template = """Answer the following question based on this context: {context} Question: {question} """