浅谈ChatGPT
下面谈一谈我对chatGPT的简单认知,这也是看了许多资料总结出来的,没有去实际去研究chatGPT的代码,我姑且言之,有兴趣的同学姑且听之。
去年chatGPT大火,才让我们对人工智能有了更深一步的了解。之前认为的智能聊天就是像那些客服机器人一样,反反复复就那么几句话,跟智障一样,现在看到chatGPT这么厉害,宛若神明。
归根到底的数学概率
其实大家可以简单理解,chatGPT的语言生成是一个数学概率模型,他的一个词语到生成下一个词语是采用概率最大的词语生成,就比如说,你输入一堆数据提供chatGPT训练,其中词语A后面接词语B的次数最多也就是概率最大,那么下次chatGPT给你生成回复的时候词语A后面接词语B的概率也最大。当然这也是简单说,实际肯定没这么简单。如下图,伟大的国家 这个概率是99%,拎一个选项是1%。那自然会生成 中国是个伟大的国家 。

语言模型的两个方向
其实在语言模型这块一直有两个方向,一个是语义理解,一个是语句生成。语义理解是谷歌主要研究的方向,这个类似于完形填空。而语句生成是0penAI的主要方向,也就是我们现在看到的chatGPT,这个类似于写作文。这两种的应用环境和使用的算法也是不一样的,简单的说一下,语义理解,是根据前后文,两个维度计算出中间的缺失,谷歌已经做到了很高的准确率,这就对我们英语考试中的完形填空很友好了。而语句生成就跟我们写作文一样,从头写到尾,只有一个维度支撑。这就是谷歌Bert和openAI的ChatGPT的差别,双向和自回归。

数学+技术
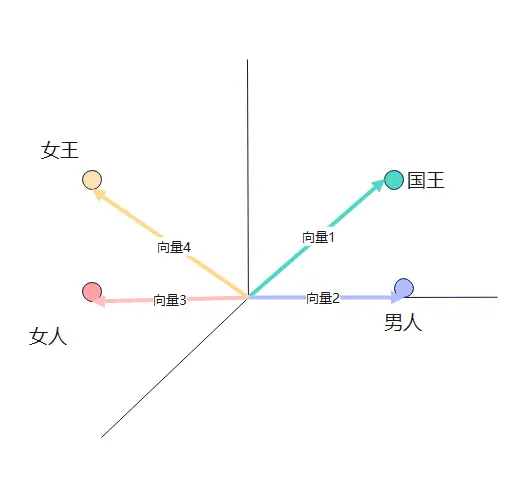
Bert和ChatGPT都是基于Transformer实现的,啥是Transformer呢,简单理解就是我们上面说的根据概率最大生成文字。只不过这生成的实现很复杂,大概说-下,我们输入的句子会被拆分成一个一个的单词(token),根据这些单词计算向量权重,最后根据这些解析拆分后的向量权重计算概率生成输出。这些向量是怎么计算的呢,我们看个例子,国王-男人+女人=女王,这种向量的计算是不是很有意思。
监督学习
当然上面的过程也只是其中的训练的一环,还有重要的监督学习。ChatGPT根据概率输出的东西很难保证准确性,毕竟是没有思想的机器,所以这时候就需要我们监督学习,给他的输出打分,正确的分数就高,错误的分数就低,这要提高了正确回答的权重,也就影响了概率和输出。

总结
网上好多资料说了一大堆高大尚的名词:深度学习、循环神经网络、自然语言处理技术、注意力机制、损失函数。这些都是具体实现,不做ai 的也没必要深入了解,知道chatGPT的大概原理也就够了。目前好多人说chatGPT的出现会对现在的社会造成巨大的冲击,绝大多数人都会失业。我想说这并不一定,上面也说了人工智能是根据概率推算结果的,这个概率是根据已有事件计算的,类似于绝大多数人说啥,他也会说啥。这也就是说,他是没有创造力的,他只能帮我们整理已有事件,不会突破已有的事件。比如说当绝大多数人都认为地球是-个平面的时候,chatGPT也会认为地球是一个平面,不会有思考发现地球是个球体。人工智能只是解放了我们生产力,让我们有更多的时间去完成一些创造性的事情。但是如果我们一直在做这种重复性的事情,没有思考创新,chatGPT的出现对我们来说绝对会是个巨大的灾难,至少摸鱼的机会会大大减少。
