知识库原理
简介
现在大模型大行其道,我们普通人没有那么多资源,有没有办法搭建一个大模型玩一下呢,答案肯定是有的,我们可以搭建一个知识库,用一下大模型。
总所周知,大模型的训练是需要大量资源的,我们没有这么多资源,那我们就得想办法绕过训练或者减少训练。这时候知识库就是一个比较好的选择,它不需要对大模型进行大量的训练,大模型只是帮我们生成一个类人话的答案。
架构
目前比较用的比较多的就是LangChain框架,这是一种基于Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。
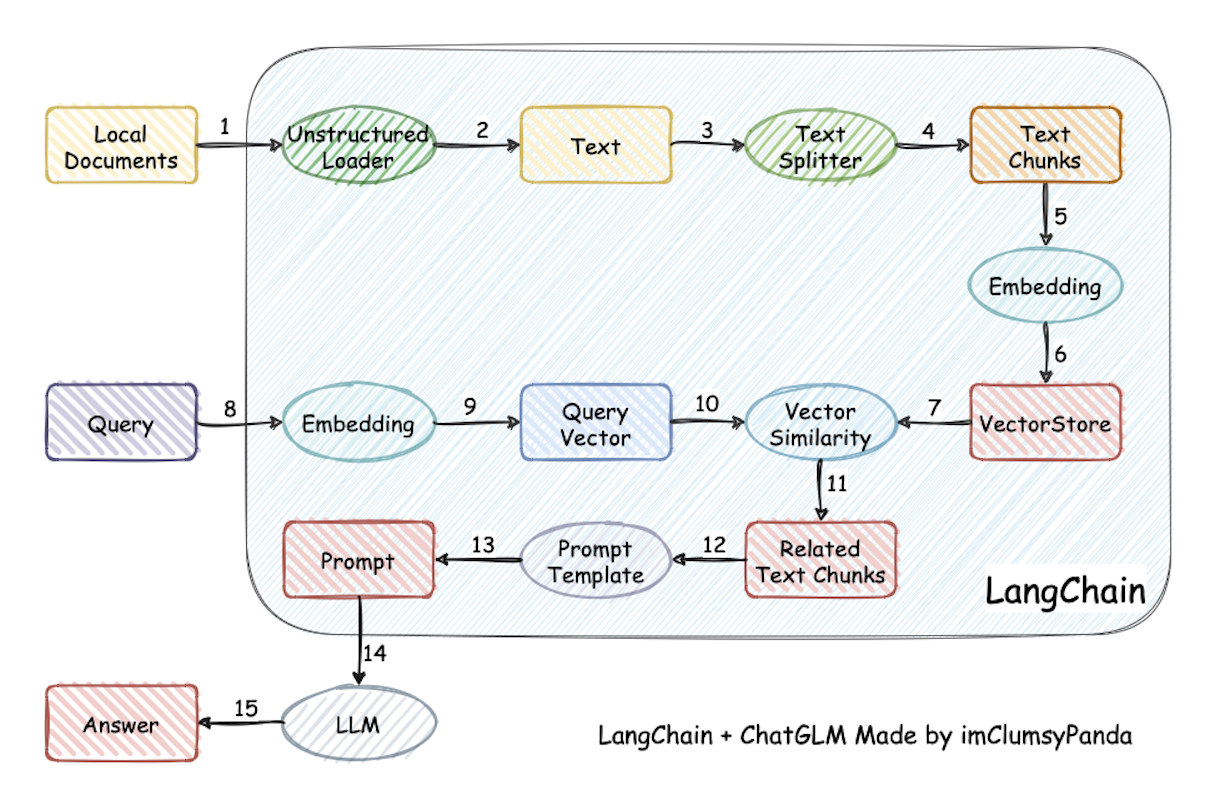
可以从上面的原理图看出知识库的整个实现原理。
1、先加载文件,文件可以是结构化的也可以是非结构化的
2、读取文本,这就很好理解了,将加载进来的文件读取
3、分割文本,将读取的文本分割成一段一段的,便于提取其中的关键字和让内容更内敛
4、向量化,将分割后的文本向量化,
5、存储,将向量化后的文本存入向量数据库中,当然可能也有一些结构型数据,直接存入关系型数据库中
6、问句向量化,将我们提问的问句给向量化,理论上和上面的文本向量化一样,问句也是一个文本
7、向量化匹配,通过问句的向量去向量库里面匹配文本,可能会匹配出多个,我们只取top n
8、生成prompt,将匹配到的文本作为上下文和问题一起生成prompt
9、将prompt提交给LLM生成回答
上面就是知识库的原理和流程。可以看到,其实大模型在这里只是扮演一个类人化回答生成的作用,回答中的知识点其实都是在向量化匹配的过程中匹配出来的。所以这里不需要大模型做大量的训练。
LangChain只是做了一个框架,上面的原理和流程也只是一个大纲,具体的细节我们还是有很多可操控空间的。
比如说文本分割,框架提供的默认分割方法是分割到什么程度,我们需要的又是分割到什么程度,如果框架提供的分割粒度比较答,一篇文章分割之后,分割成了几个大段,我们后面匹配到了,一起放到大模型中生成回答也是一个巨大的计算量或者有些大模型都不支持,文本大了,相当于参数就多了,那生成回答的计算量就变大了,甚至有些参数都支持不了这么多参数。
在比如说,在向量匹配的过程中,我们只能使用框架提供的匹配方法嘛,当然不是,毕竟框架不可能面面俱到,我们可能要做一些权重微调,或者换一种算法,再或者有的时候需要我们去关系型数据库中匹配。
最后,既然大模型只是一个生成类人回答的作用,那我们是不是就可以把LLM就是一个接口,其中具体是什么大模型,我们不是特别关注,毕竟只要能给我们根据知识点生成一段通顺的回答就行,至于是LangChain还是chatGLM,又或者是阿里清华的大模型,我们都不是特别关注。