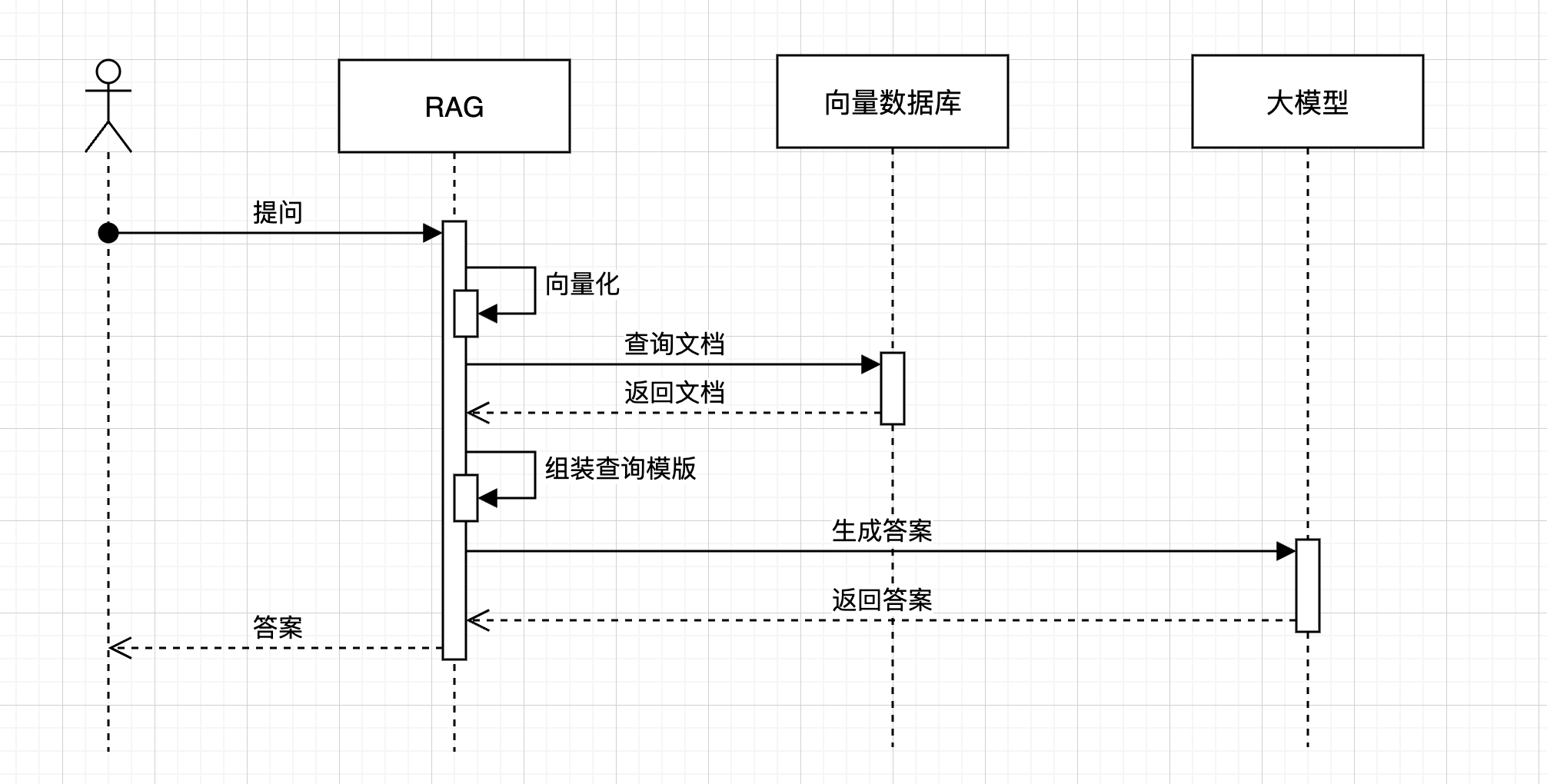
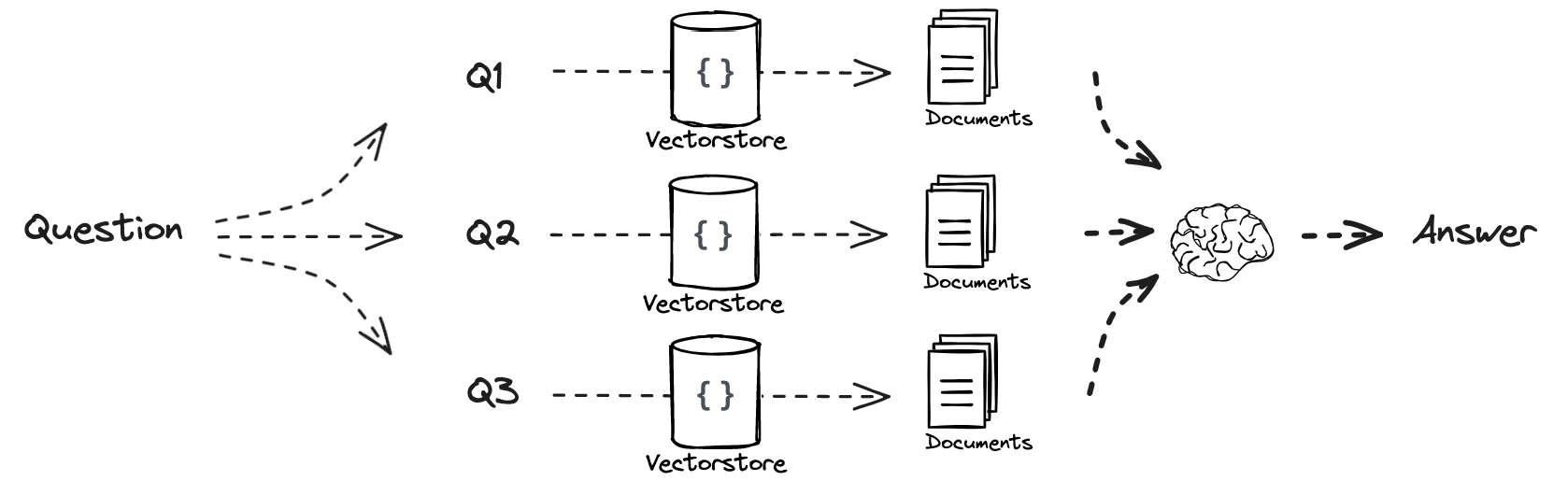
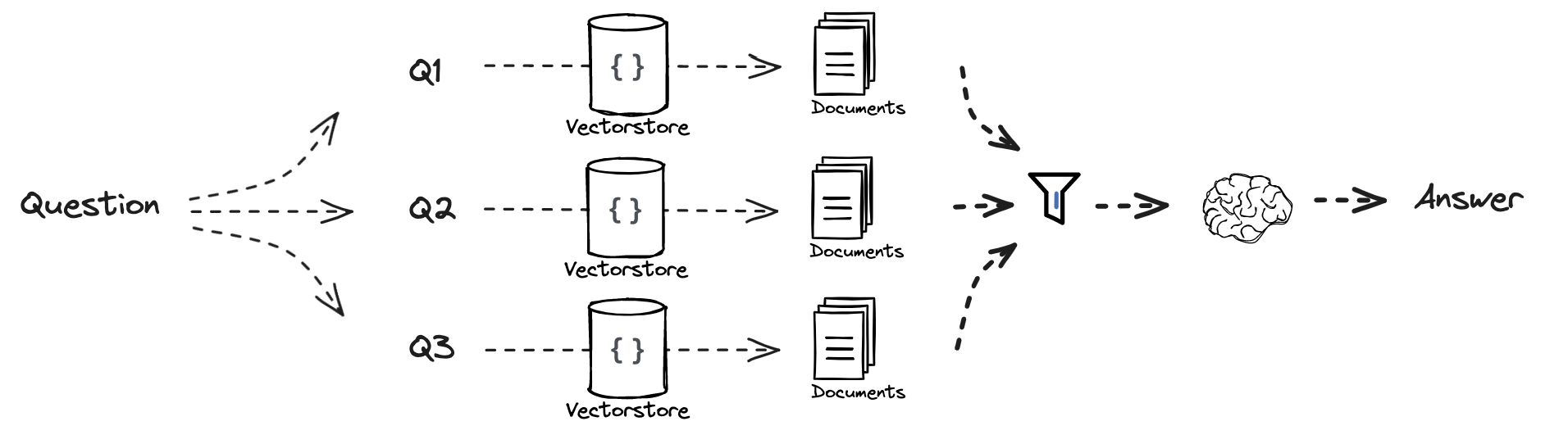
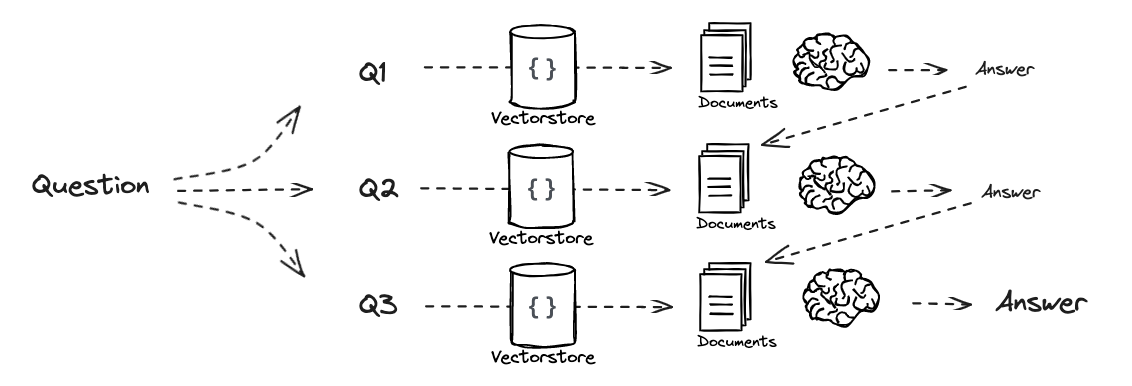
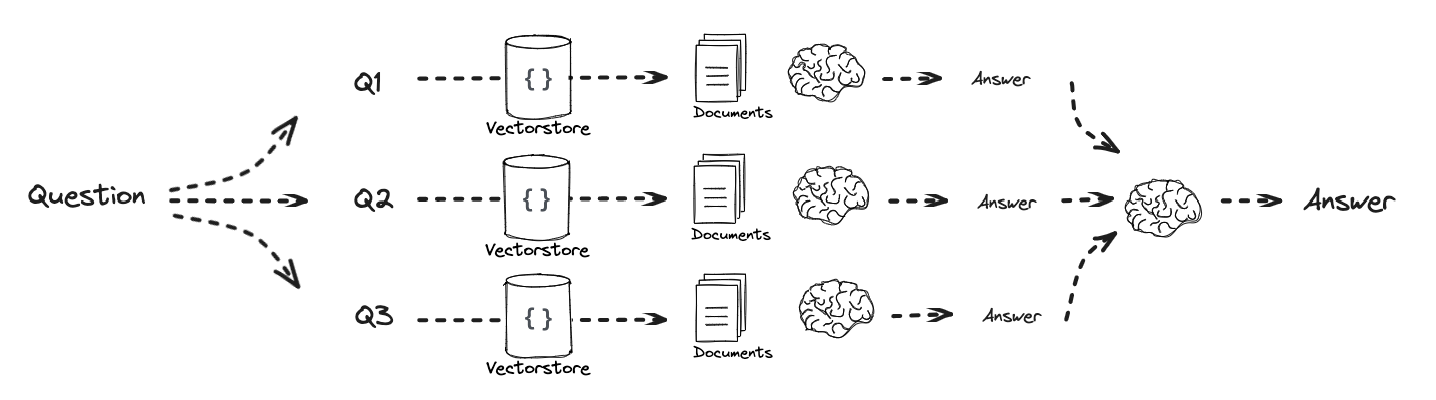
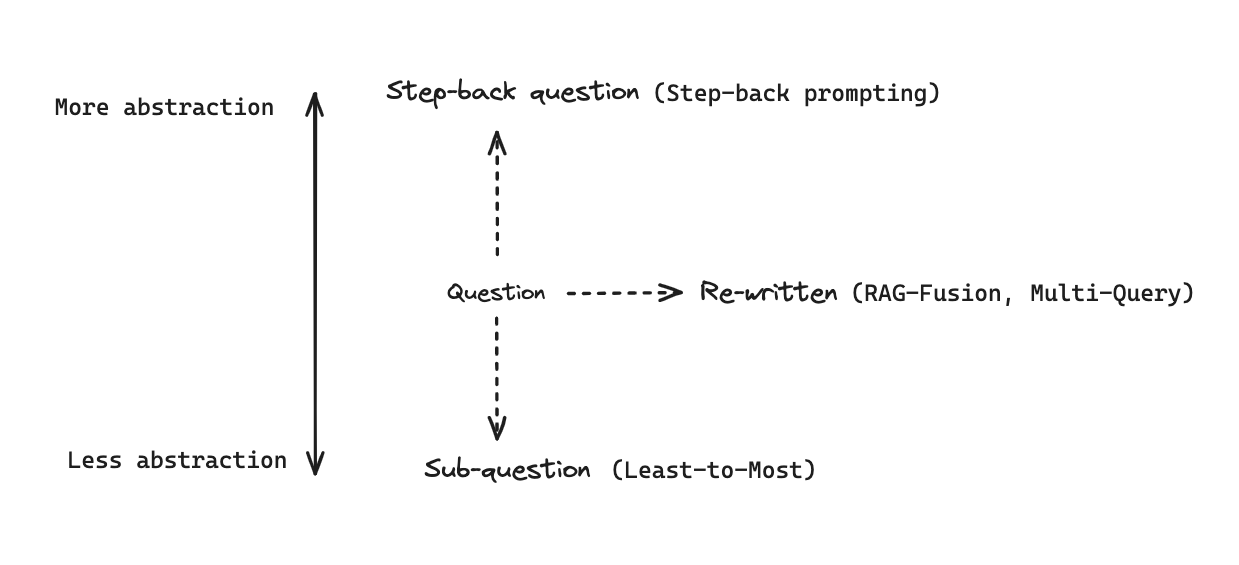
# Multi Query: Different Perspectives template = """You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}""" prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI
defget_unique_union(documents: list[list]): """ Unique union of retrieved docs """ # Flatten list of lists, and convert each Document to string flattened_docs = [dumps(doc) for sublist in documents for doc in sublist] # Get unique documents unique_docs = list(set(flattened_docs)) # Return return [loads(doc) for doc in unique_docs]
defreciprocal_rank_fusion(results: list[list], k=60): """ Reciprocal_rank_fusion that takes multiple lists of ranked documents and an optional parameter k used in the RRF formula """ # Initialize a dictionary to hold fused scores for each unique document fused_scores = {}
# Iterate through each list of ranked documents for docs in results: # Iterate through each document in the list, with its rank (position in the list) for rank, doc inenumerate(docs): # Convert the document to a string format to use as a key (assumes documents can be serialized to JSON) doc_str = dumps(doc) # If the document is not yet in the fused_scores dictionary, add it with an initial score of 0 if doc_str notin fused_scores: fused_scores[doc_str] = 0 # Retrieve the current score of the document, if any previous_score = fused_scores[doc_str] # Update the score of the document using the RRF formula: 1 / (rank + k) fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results reranked_results = [ (loads(doc), score) for doc, score insorted(fused_scores.items(), key=lambda x: x[1], reverse=True) ]
# Return the reranked results as a list of tuples, each containing the document and its fused score return reranked_results
# Decomposition template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n Generate multiple search queries related to: {question} \n Output (3 queries):""" prompt_decomposition = ChatPromptTemplate.from_template(template) from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser
# Run question = "What are the main components of an LLM-powered autonomous agent system?" questions = generate_queries_decomposition.invoke({"question":question}) # Prompt template = """Here is the question you need to answer: \n --- \n {question} \n --- \n Here is any available background question + answer pairs: \n --- \n {q_a_pairs} \n --- \n Here is additional context relevant to the question: \n --- \n {context} \n --- \n Use the above context and any background question + answer pairs to answer the question: \n {question} """
decomposition_prompt = ChatPromptTemplate.from_template(template) from operator import itemgetter from langchain_core.output_parsers import StrOutputParser
defformat_qa_pair(question, answer): """Format Q and A pair""" formatted_string = "" formatted_string += f"Question: {question}\nAnswer: {answer}\n\n" return formatted_string.strip()
from langchain import hub from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI
defretrieve_and_rag(question,prompt_rag,sub_question_generator_chain): """RAG on each sub-question""" # Use our decomposition / sub_questions = sub_question_generator_chain.invoke({"question":question}) # Initialize a list to hold RAG chain results rag_results = [] for sub_question in sub_questions: # Retrieve documents for each sub-question retrieved_docs = retriever.get_relevant_documents(sub_question) # Use retrieved documents and sub-question in RAG chain answer = (prompt_rag | llm | StrOutputParser()).invoke({"context": retrieved_docs, "question": sub_question}) rag_results.append(answer) return rag_results,sub_questions
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
defformat_qa_pairs(questions, answers): """Format Q and A pairs""" formatted_string = "" for i, (question, answer) inenumerate(zip(questions, answers), start=1): formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n" return formatted_string.strip()
context = format_qa_pairs(questions, answers)
# Prompt template = """Here is a set of Q+A pairs: {context} Use these to synthesize an answer to the question: {question} """
# Few Shot Examples from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate examples = [ { "input": "Could the members of The Police perform lawful arrests?", "output": "what can the members of The Police do?", }, { "input": "Jan Sindel’s was born in what country?", "output": "what is Jan Sindel’s personal history?", }, ] # We now transform these to example messages example_prompt = ChatPromptTemplate.from_messages( [ ("human", "{input}"), ("ai", "{output}"), ] ) few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) prompt = ChatPromptTemplate.from_messages( [ ( "system", """You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""", ), # Few shot examples few_shot_prompt, # New question ("user", "{question}"), ] ) generate_queries_step_back = prompt | ChatOpenAI(temperature=0) | StrOutputParser() question = "What is task decomposition for LLM agents?" generate_queries_step_back.invoke({"question": question}) # Response prompt response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant. # {normal_context} # {step_back_context} # Original Question: {question} # Answer:""" response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = ( { # Retrieve context using the normal question "normal_context": RunnableLambda(lambda x: x["question"]) | retriever, # Retrieve context using the step-back question "step_back_context": generate_queries_step_back | retriever, # Pass on the question "question": lambda x: x["question"], } | response_prompt | ChatOpenAI(temperature=0) | StrOutputParser() )
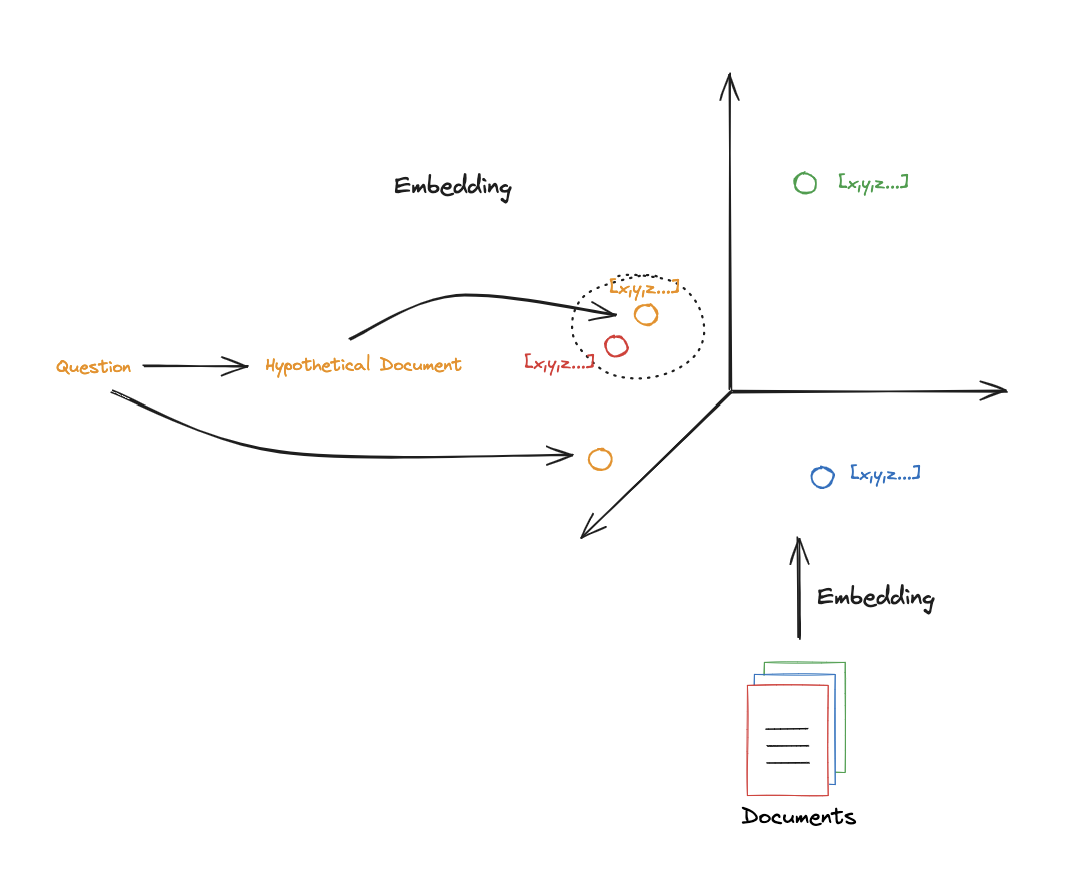
# Run question = "What is task decomposition for LLM agents?" generate_docs_for_retrieval.invoke({"question":question}) # Retrieve retrieval_chain = generate_docs_for_retrieval | retriever retireved_docs = retrieval_chain.invoke({"question":question}) retireved_docs # RAG template = """Answer the following question based on this context: {context} Question: {question} """