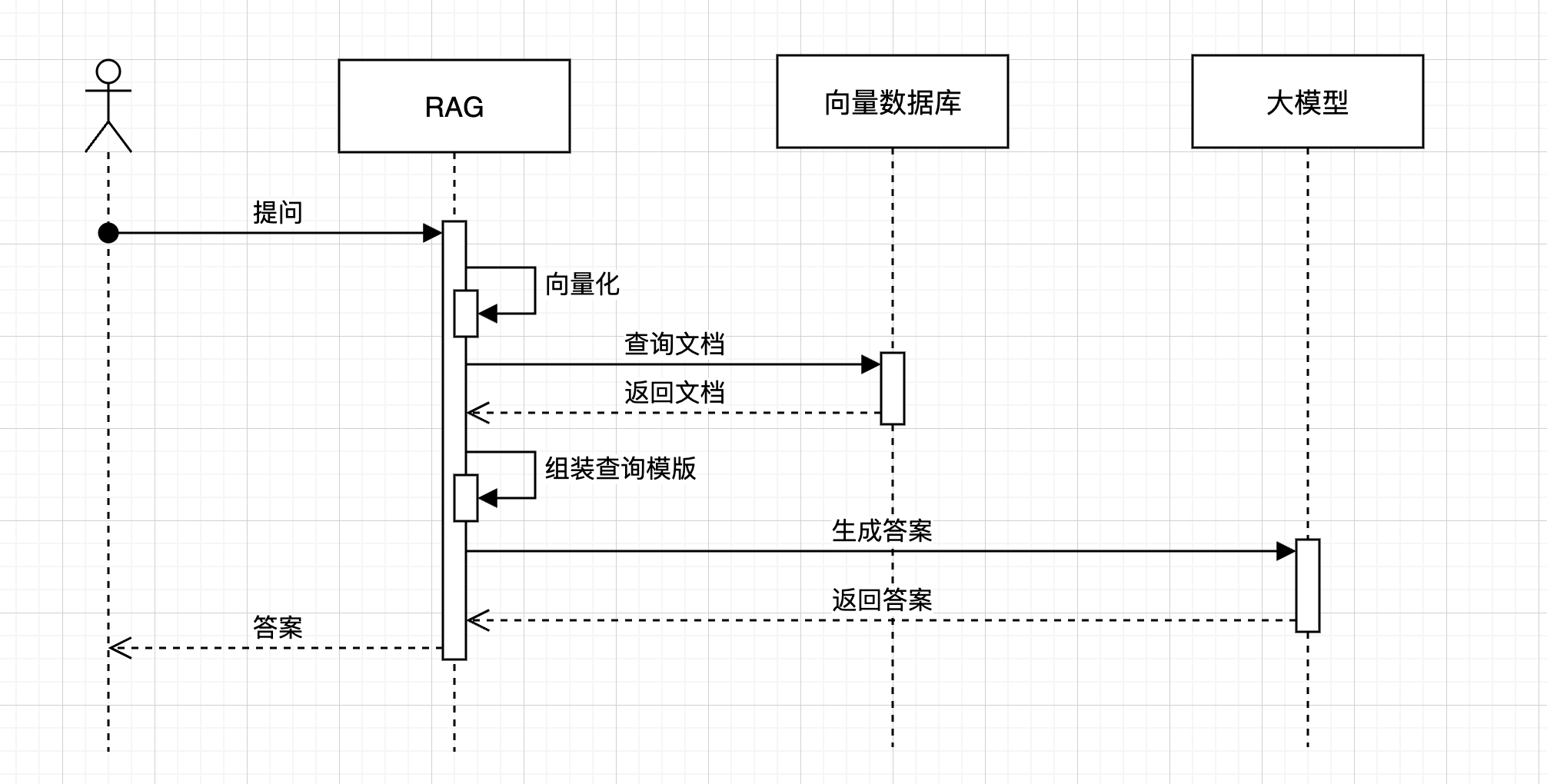
简述 RAG的主流程其实比较简单,流程前面已经说过了,简单看一下下面的图了解一下就行。
从上面的图,可以看到,RAG在回答用户问题的时候,向量数据库的交互式非常重要的一环,如果我们能提高向量库的召回质量也就能提高整个答案生成的质量。
强化索引 现在我们知道提高向量库的召回质量能提高整个提问答案的生成质量,怎么提高向量库交互的召回质量有成了新的问题。之前我们说过向量库的查询召回是通过向量的比较实现的,与提问越相近的向量被召回的概率越高。现在我们只要提高文档的向量质量,这样才能提高查询召回的准确性和质量。
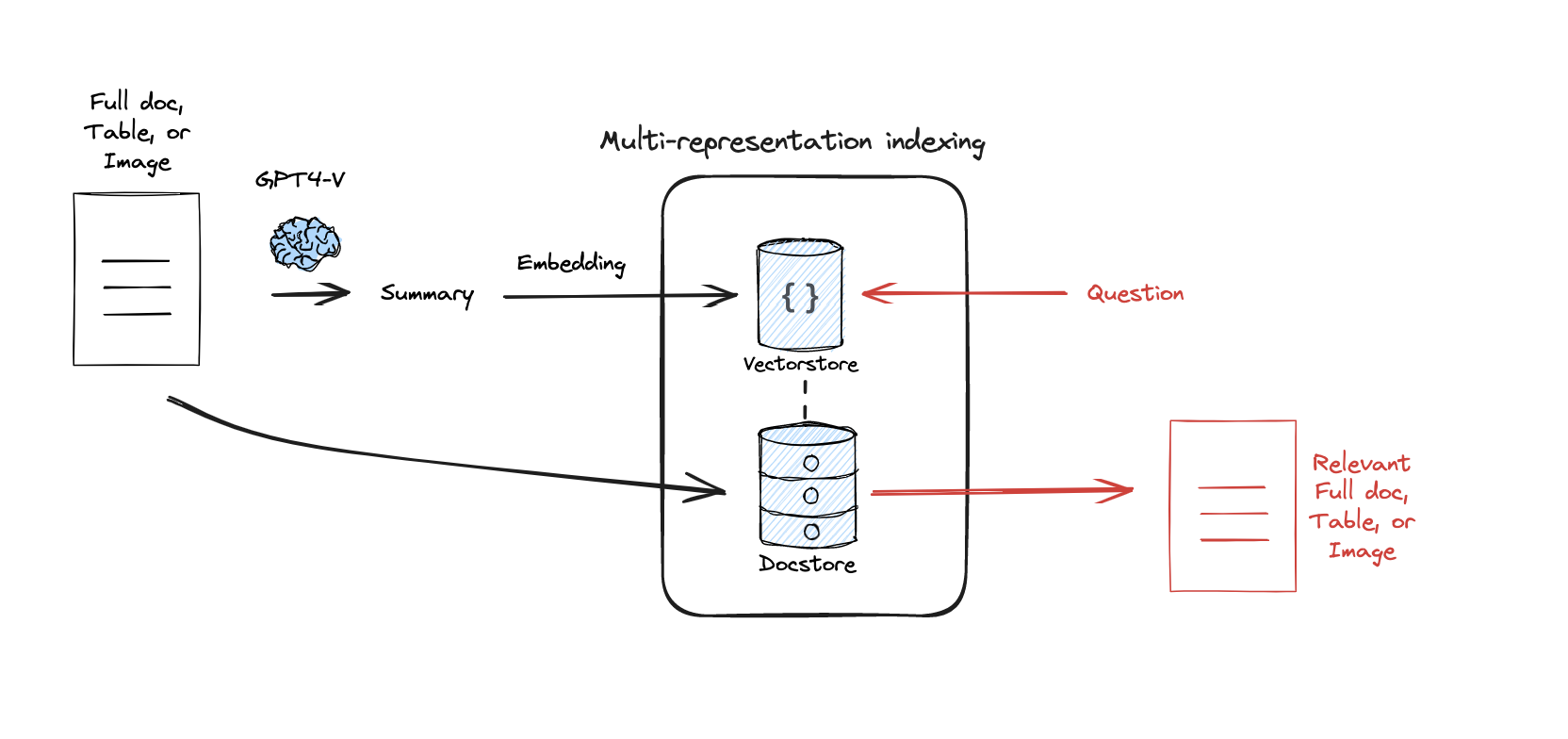
MRI MRI(Multi-representation Indexing)多表示强化索引,为每个文档构建多个不同视角的向量表示 。其实这个很好理解,我们一句话从不同的角度去理解包含了不同的信息,比如“我今天下午在写博客”这句话,第一个角度理解,就是字面意思,我今天下午写博客,换一个角度,我今天下午还活着,不然也不能写博客。从上面的示例,我们从两个角度获得了两个信息,推广一下,一段话、一篇文章也一样,不同的角度的理解能得到不同的信息,也就能根据这些不同的信息生成不同的向量。
不同维度的理解更加丰富了文章的定义,不同维度的理解也催生了多向量多文章的描述,从而使文章的向量定义更加准确,也使我们查询召回的时候更加准确。
在实际应用中,我们多以父子文档的方式去处理MRI,父文档是原始文档,子文档都是对父文档的摘要、标题等多维度理解表达,我们通过将子文档存入向量库,通过提问向量匹配召回后,通过这些理解表达再找回父文档返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import uuidfrom langchain_core.documents import Documentfrom langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromafrom langchain.storage import InMemoryByteStorefrom langchain.retrievers.multi_vector import MultiVectorRetrieverraw_docs = [ "LangChain is a framework for developing applications powered by language models." , "Chroma is a vector database used for similarity search over embeddings." ] summaries = [ ["LangChain is a framework for LLM apps." , "It helps chain language model calls." ], ["Chroma is a vector store." , "It supports similarity search for embeddings." ] ] doc_ids = [str (uuid.uuid4()) for _ in raw_docs] summary_docs = [] for i, summary_list in enumerate (summaries): for s in summary_list: summary_docs.append(Document(page_content=s, metadata={"doc_id" : doc_ids[i]})) embedding_function = OpenAIEmbeddings() vectorstore = Chroma(collection_name="multi_index_demo" , embedding_function=embedding_function) byte_store = InMemoryByteStore() id_key = "doc_id" retriever = MultiVectorRetriever( vectorstore=vectorstore, byte_store=byte_store, id_key=id_key, ) retriever.vectorstore.add_documents(summary_docs) retriever.docstore.mset(list (zip (doc_ids, raw_docs))) query = "What is a vector database?" results = retriever.get_relevant_documents(query, n_results=1 ) print ("🔍 用户查询:" , query)print ("📄 匹配到的原始文档:" , results[0 ].page_content)
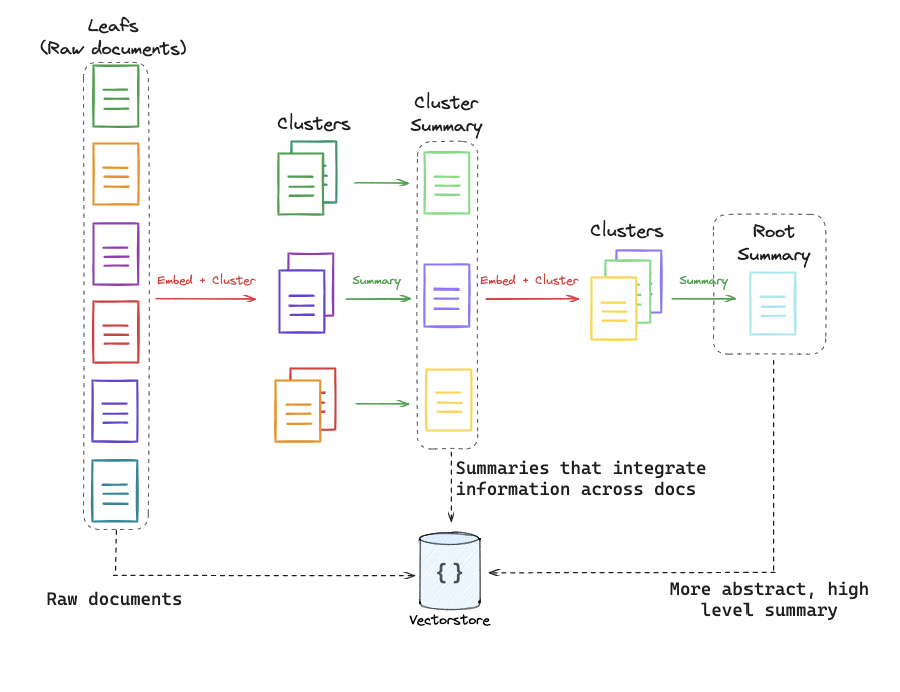
RAPTOR RAPTOR 是一种 高效构建多表示索引(multi-representation indexing)的新方法 ,上面的MRI相当于多维度广度上的处理,一般有广度处理就有深度处理。刚才是从维度上对文章做的处理,现在我们从深度上做处理。我们可以将一篇文章拆分成多个段落,然后对每个段落进行提炼总结,总结出一个个标题,再对这些标题做呢向量处理,生成出向量,这样我们查询到的是一个个段落,这样我们的查询结果会更加精准。
RAPTOR 的核心思想是:先用结构化方法将文档拆分为多个子块(chunk),再用 LLM 为每个子块生成一个有语义的标题作为向量索引的表示 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from langchain_core.documents import Documentfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_community.vectorstores import FAISSllm = ChatOpenAI(model="gpt-4" ) embed = OpenAIEmbeddings() chunks = [...] title_chunks = [] for chunk in chunks: title = llm.invoke(f"为以下内容生成一个主题标题:\n\n{chunk} " ) title_chunks.append(Document(page_content=title, metadata={"chunk" : chunk})) vectorstore = FAISS.from_documents(title_chunks, embed)
ColBERT ColBERT (Column-wise BERT )改进语义检索质量的深度表示方法 ,但它的思路和实现非常独特,ColBERT 是一种 细粒度(token-level)语义检索方法 ,它把文档和查询都表示成 多个 token 向量 ,然后通过 最大相似度匹配机制 来计算查询与文档的相关性,从而提升精度和效率。和上面的REAPTOR 类似单不同,REAPTOR是拆分子块,然后生成标题,这个ColBERT直接就拆分成token了,可以理解为拆分的更细更碎,且没有提炼生成标题的阶段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from ragatouille import RAGPretrainedModelimport requestsRAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0" ) def get_wikipedia_page (title: str ): URL = "https://en.wikipedia.org/w/api.php" params = { "action" : "query" , "format" : "json" , "titles" : title, "prop" : "extracts" , "explaintext" : True , } headers = {"User-Agent" : "ColBERT-example/0.0.1 (your_email@example.com)" } response = requests.get(URL, params=params, headers=headers) data = response.json() page = next (iter (data["query" ]["pages" ].values())) return page["extract" ] if "extract" in page else None doc_text = get_wikipedia_page("Hayao Miyazaki" ) RAG.index( collection=[doc_text], index_name="miyazaki-demo-index" , max_document_length=180 , split_documents=True ) query = "Which animation studio did Miyazaki found?" results = RAG.search(query=query, k=3 ) for rank, hit in enumerate (results, 1 ): print (f"Rank {rank} :" ) print ("Score:" , hit['score' ]) print ("Passage:\n" , hit['content' ]) print ("=" * 80 )
三者异同 我们来详细对比 MRI(Multi-representation Indexing) 、RAPTOR 和 ColBERT 三者的异同点 。
特性
MRI
RAPTOR
ColBERT
📌 核心思路
为同一段文本生成多个不同视角的表示向量 (如主题、意图、关键词等)
将文档划分为语义段(小粒度),为每段生成简洁标题(父文档) 作为召回锚点
将文本拆成 token 粒度 ,用户 query 也拆成 token,然后进行 token 级别的Late Interaction 匹配
🎯 优势
多角度语义增强召回 ,能捕捉不同用户提问方式结构化文档、压缩检索空间 ,提高精确召回率
更细粒度的匹配,可解释性强 ,适合长文高密度信息检索
🧩 粒度
Chunk/Paragraph 级
Paragraph + Title
Token 级别
🧠 表示方式
多向量(multi-head)
父子文档(title-child)
Token-level 表示
📦 模型类型
通常是 dense encoder(可多次 encode)
标题生成模型 + Dense encoder
特殊结构模型(支持 Late Interaction),如 ColBERT 模型
🧪 检索方式
向量 ANN
父文召回 + 子文 rerank
Token-Level MaxSim 聚合
🧰 代表实现
HyDE-MRI 、[NeMo RAG]RAPTOR (Hofstätter et al. 2023) ColBERT , ColBERTv2
每一种方法都有优劣,这时候你应该能很敏感的get到,如果能将三种方法综合在一起应该是个很棒的方案,那这个方案是否存在呢,肯定是存在的。如下流程整合:
文档分割(RAPTOR) :
用 RAPTOR 的方式划分语义段落,为每段生成标题(构建父子结构);
多表示索引(MRI) :
对每段生成多种视角的表示向量(主题向量 + 关键词向量 + 语义向量);
Token-level 检索(ColBERT) :
用户 Query 使用 ColBERT 拆成 token 粒度匹配以 rerank 最终结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 from ragatouille import RAGPretrainedModelfrom transformers import pipelineimport requestsRAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0" ) title_generator = pipeline("text2text-generation" , model="google/flan-t5-base" ) def get_wikipedia_page (title: str ): URL = "https://en.wikipedia.org/w/api.php" params = {"action" : "query" , "format" : "json" , "titles" : title, "prop" : "extracts" , "explaintext" : True } headers = {"User-Agent" : "ColBERT-MRI-RAPTOR/0.0.1 (you@domain.com)" } resp = requests.get(URL, params=params, headers=headers) page = next (iter (resp.json()["query" ]["pages" ].values())) return page.get("extract" , "" ) def split_and_title (document ): chunks = [chunk for chunk in document.split("\n\n" ) if len (chunk.strip()) > 100 ] titled_chunks = [] for chunk in chunks: title = title_generator(f"Generate title: {chunk[:200 ]} " , max_new_tokens=12 )[0 ]["generated_text" ] titled_chunks.append({"title" : title, "content" : chunk}) return titled_chunks def multi_view_representations (titled_chunks ): views = [] for chunk in titled_chunks: views.append(chunk["content" ]) views.append(chunk["title" ]) views.append("Keywords: " + ", " .join(chunk["content" ].split()[:10 ])) return views def index_document (title ): full_text = get_wikipedia_page(title) titled_chunks = split_and_title(full_text) mri_texts = multi_view_representations(titled_chunks) RAG.index(collection=mri_texts, index_name=f"RAG-MRI-RAPTOR-{title} " , max_document_length=180 ) def search (query, k=3 ): results = RAG.search(query=query, k=k) for i, hit in enumerate (results, 1 ): print (f"Rank {i} : [Score: {hit['score' ]:.2 f} ]" ) print (hit['content' ]) print ("=" *80 ) index_document("Hayao Miyazaki" ) search("Which animation studio did Hayao Miyazaki found?" )