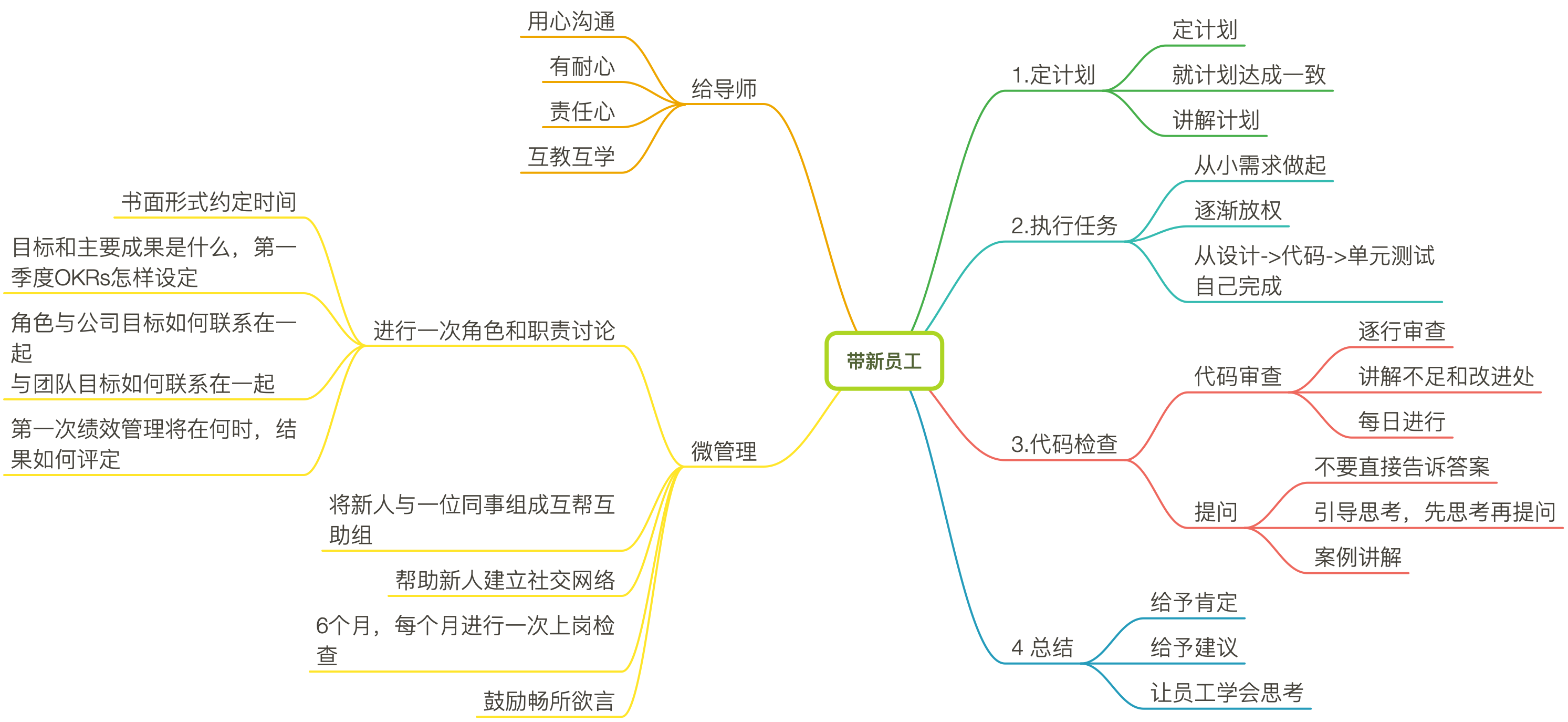
深度学习
在大模型大行其道的今天,学习使用大模型已经是我们程序猿不可或缺的一部分。网传的大模型神乎其神,貌似无所不能,那么大模型的底层到底是什么,是怎么一步一步的发展到今天的大模型的呢。其实大模型的底层本质就是深度学习,只不是跟我们了解的深度学习不一样的是大模型的参数比较多,甚至可以说多的可怕。了解完深度学习之后你就知道为什么参数可以作为大模型的一个指标了。
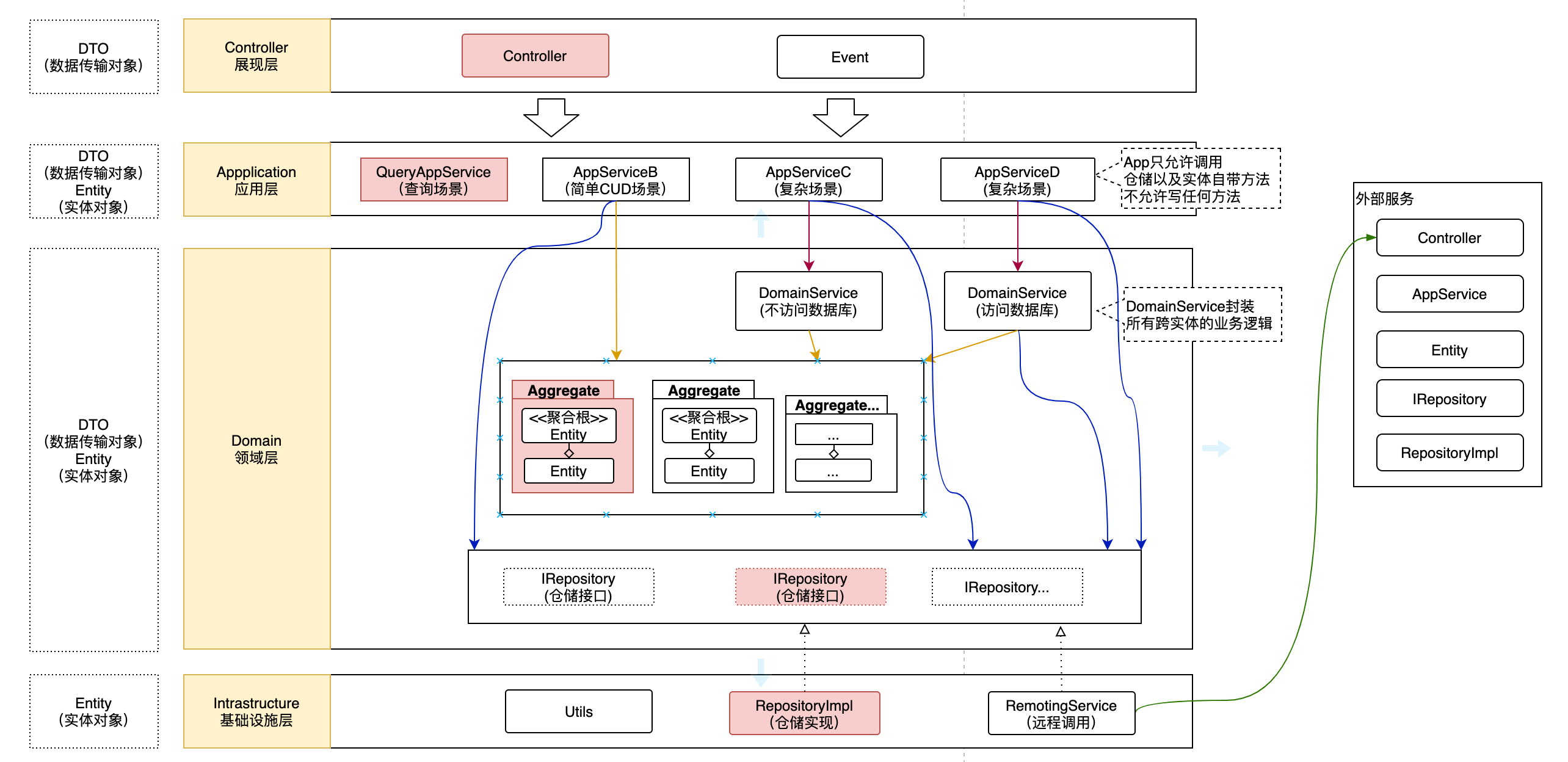
其实深度学习大致可以划分成三步:构建函数模型、计算缺失值、优化。
案例背景
已知店铺A,11月份每一天的每一天的营业额,我们怎么计算预测12月前3天的营业额。

简单模型预测
按照我们上述说的三个步骤,将整个过程划分成三步,构建函数模型,计算缺失值,计算参数。
构建函数模型
这里我们先构建一个简单的预测模型,其实预测模型就是一个关系函数,就是被预测的结果和前面输入之间的关系函数,在这里就是12月前3天的营业额和11月营业额之间的关系。关系函数我们表示为 y=f(x),在这里我们先构建一个最简单的预测模型,假设后一天的营业额和前一天的营业额之间的关系函数是 y=ax+b,y是后一天我们预测的营业额,x是当日的营业额。
计算缺失值
现在我们知道了营业额之间的预测函数和11月整个月的营业额,这样我们就可以计算出整个11月真是营业额和我们预测函数计算出来的预测营业额之间的差值L。
$$
L=\frac{1}{N} \Sigma(|y- \hat{y}|)
$$
上面的公式,就是11月的预测值和实际值的差值求平均值。如果我们随机选取一个较小的a、b的初始值,就能计算出缺失值L的值,当我们不停的变幻a、b值之后,就会得到不同的L值。不同的a、b值和L可以构建出下图这样一个统计图,其中蓝色区域是L的较小值,红色是交大值。

计算参数
根据公式,我们是能算出缺失值L的,但是由于我们的预测模型是 y=ax+b,那么我们的缺失值的结果这也一定包含着这两个参数,换而言之就是这两个参数影响着我们的计算结果缺失值L。实际情况中,我们总是希望误差越小越好,也就是缺失值L越小越好。
在数学中,我们求最小值,一般都和斜率相关,找到L的斜率等于0的值,我们应该就能找到一个合适a、b值。我们将L对a、b求偏导,就能找到L相对小的点。这样也就得出了合适的a、b值,从而得到了一个合适的预测函数y=ax+b。

优化
上面我们只是选了一个最简单的折线模型去计算预测值,折线模型只是最简单的模型,在本质上就有所不足,不能很好的预测多参数曲线值。如下图,如果我们用折线模型去模拟计算那条红色的折线,就不是很好计算模拟。如果我们多加几个参数,就比较好计算模拟了。
可以使用sigmoid(x)的函数(下图蓝色折线1),多几个参数模拟出红色折线。蓝色折线0、1、2、3相加就等于红色折线,折线0是一个常数a,折线2是 csigmoid(x+b),折线3是dsigmoid(x+e)。从而得出:*
y=sigmoid(x) + a + csigmoid(x+b) + d*sigmoid(x+e)
$$
y=b+\sum_iC_i*sigmoid(b_i+w_ix)
$$
同时我们可以看到,销售额呈周期性变化。我们可以通过一个周期内销售额去计算预测值,公式如下。
$$
y=b+\sum_ic_isigmoid(b_i+\sum_jw_{ij}x_j)
$$

我们根据上面的公式可以计算出预测值,上述的公式5得出,如果我们计算出在得知前三个销售额的情况下,预测出的销售额。

上面的演示结果可以得出
$$
y = b + \sum_i c_i sigmoid(r_i)
$$
如果我们将 sigmoid(r) 看出一个整体的话,可以简化成
$$
y = b + c^Ta
$$
整个公式:
$$
y=b+c^Ta = b+c^T * \sigma(b+wx)
$$
注意上面的两个b不是同一个值。
整个计算逻辑,如图展示:

上面的计算模型只是模拟计算了一层,我们可以模拟计算多层,深度学习的本质就是让我们模拟计算跟多的层次以达到更好的效果,如果我们模拟计算两层的话,可以将我们第一层计算出来的a,再来一次计算。
 总结
总结
总结
整个深度学习的过程就是推导出一个合适的计算模型。推导模型的过程可以分为三步:构建函数模型,计算缺失值,计算参数。在后面的优化过程中,我们总共优化了三个点:
1、模型替换,更换成了一个更有弹性的模型
2、增加模型输入,以上述销售额为例,从前一天的销售额预测后一天的销售额变成前几天的销售额预测后一天
3、增加训练层数,将一层计算变成多层计算