简述 都知道spring的自动加载是通过注解实现的,但是这注解又是怎么实现的呢?
通过@SpringBootApplication注解开启,读取配置文件中的配置类,然后过滤掉不需要的配置类,最后将剩余的配置类加载配置。
具体过程 上面说了一下大概的概念,接下来我们分析一下具体的执行过程。
1、开启自动加载 都知道自动开启加载注解@SpringBootApplication,但是这个注解是个复合注解,他是由多个注解合并而成,但是主要的是三个注解:
1 2 3 @SpringBootConfiguration // 配置文件 @EnableAutoConfiguration // 开启自动配置 @ComponentScan // 扫描
@EnableAutoConfiguration注解继续下钻,主要有@AutoConfigurationPackage和@Import({AutoConfigurationImportSelector.class})两个注解,@AutoConfigurationPackage继续下钻主要有@Import({AutoConfigurationPackages.Registrar.class})这个注解。
所以基本可以理解
@EnableAutoConfiguration = @Import({AutoConfigurationImportSelector.class}) + @Import({AutoConfigurationPackages.Registrar.class})
即自动加载主要是依赖AutoConfigurationImportSelector.class,AutoConfigurationPackages.Registrar.class两个类。
2、@EnableAutoConfiguration下的两个类 AutoConfigurationPackages.Registrar.class:作用就是获取要扫描的包路径
1 2 3 4 5 6 7 8 9 10 11 12 static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports { Registrar() { } public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) { AutoConfigurationPackages.register(registry, (String[])(new PackageImports(metadata)).getPackageNames().toArray(new String[0])); } public Set<Object> determineImports(AnnotationMetadata metadata) { return Collections.singleton(new PackageImports(metadata)); } }
AutoConfigurationImportSelector.class:可以看到AutoConfigurationImportSelector实现了3种接口
1、DeferredImportSelector接口,继承了ImportSelector接口,用于bean的注入
2、以Aware结尾的接口,这类接口时为了完成某类资源的设置。
3、Ordered接口,用于指定bean的加载顺序。
1 public class AutoConfigurationImportSelector implements DeferredImportSelector, BeanClassLoaderAware, ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered
3、AutoConfigurationImportSelector AutoConfigurationImportSelector实现了DeferredImportSelector接口,我们先看一下DeferredImportSelector接口。
接口里就包含了要加载的bean信息,再回到实现类,主要方法process。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public void process(AnnotationMetadata annotationMetadata, DeferredImportSelector deferredImportSelector) { Assert.state(deferredImportSelector instanceof AutoConfigurationImportSelector, () -> String.format("Only %s implementations are supported, got %s", AutoConfigurationImportSelector.class.getSimpleName(), deferredImportSelector.getClass().getName())); // 获取自动配置的类 AutoConfigurationEntry autoConfigurationEntry = ((AutoConfigurationImportSelector) deferredImportSelector) .getAutoConfigurationEntry(annotationMetadata); this.autoConfigurationEntries.add(autoConfigurationEntry); // 遍历自动配置的bean for (String importClassName : autoConfigurationEntry.getConfigurations()) { // 如果存在这个类就进行加入 this.entries.putIfAbsent(importClassName, annotationMetadata); } }
其中,主要的就是获取自动配置类:getAutoConfigurationEntry方法
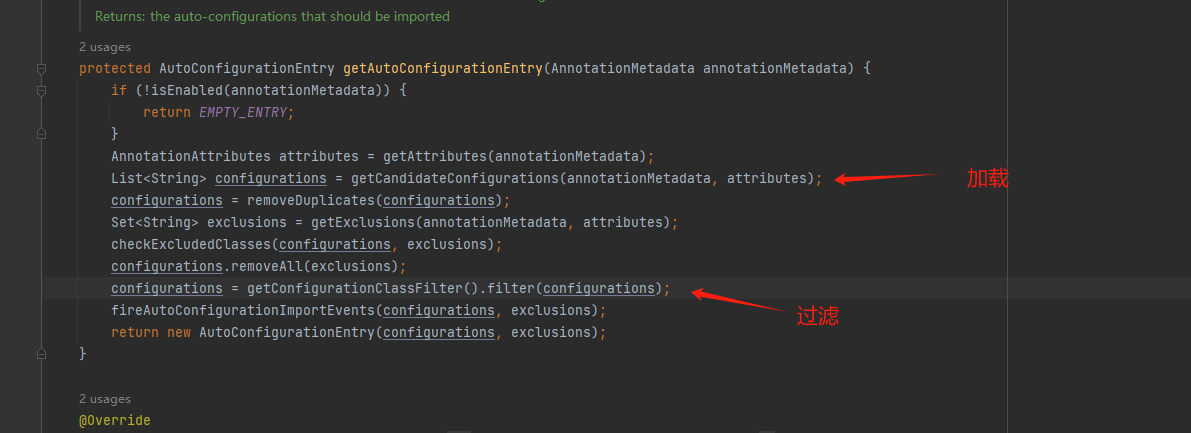
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes); // 关键
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = getConfigurationClassFilter().filter(configurations);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
}
根据关键代码继续下钻
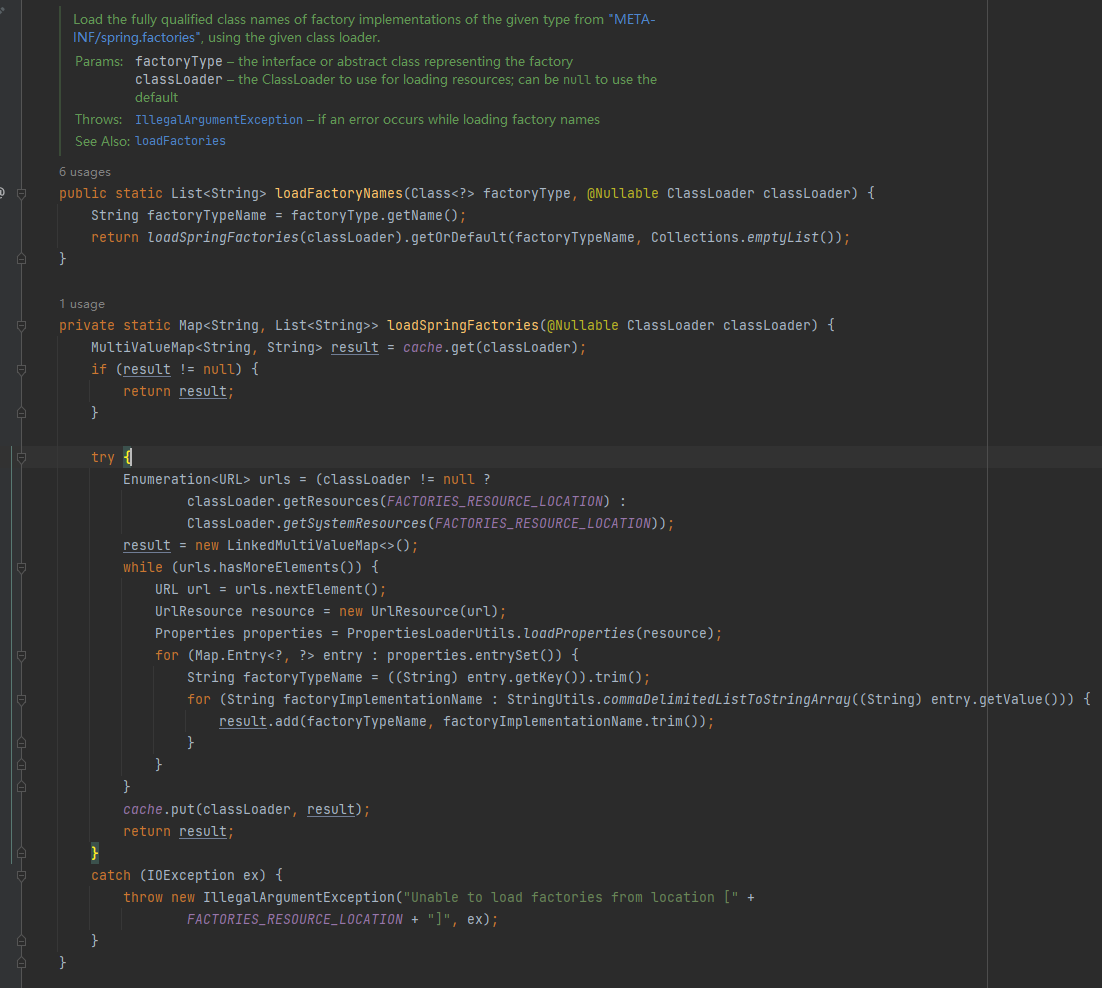
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = new ArrayList<>(
SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(), getBeanClassLoader()));
ImportCandidates.load(AutoConfiguration.class, getBeanClassLoader()).forEach(configurations::add);
Assert.notEmpty(configurations,
"No auto configuration classes found in META-INF/spring.factories nor in META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
继续下钻
到这就基本清楚了,这里加载了META-INF/spring.factories文件下的配置,然后返回到getAutoConfigurationEntry方法里进行过滤,当然过滤的方式也是按条件注解@ConditionalOnxxx过滤生效。
总结 @SpringBootApplication下分三个注解,@EnableAutoConfiguration注解负责自动加载配置,
@EnableAutoConfiguration注解又引入两个类,AutoConfigurationImportSelector.class 和 AutoConfigurationPackages.Registrar.class
主要逻辑都在AutoConfigurationImportSelector.class中,此类中有个getAutoConfigurationEntry方法,
这个方法调用了两个方法getCandidateConfigurations 加载 和 getConfigurationClassFilter().filter 过滤。
如此加载进了配置文件中的配置,过滤了条件不满足的配置,以达到开箱即用。