可复用jar包能力架构
需求描述
计划将原有的代码抽取成可复用的原子能力jar包,一个业务可能需要调用多个原子能力jar包,jar包调用链配置在配置文件中。
实现外部调用接口,通过原子能力调用链实现原子能力包调用。
主要目的:1、实现能力抽取复用,2、实现原子能力编排。
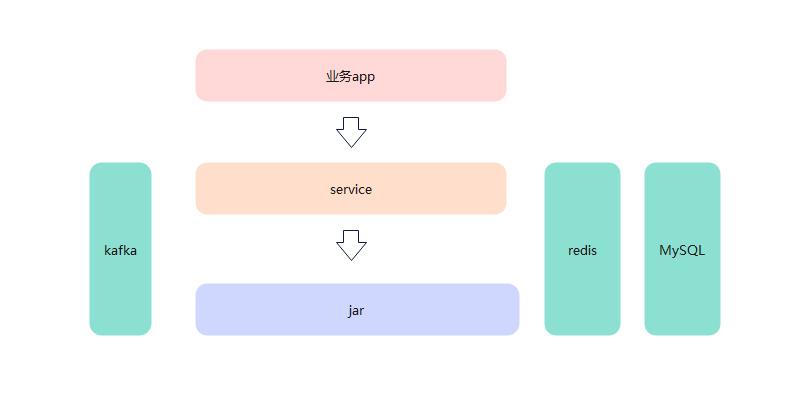
1、没有架构的架构
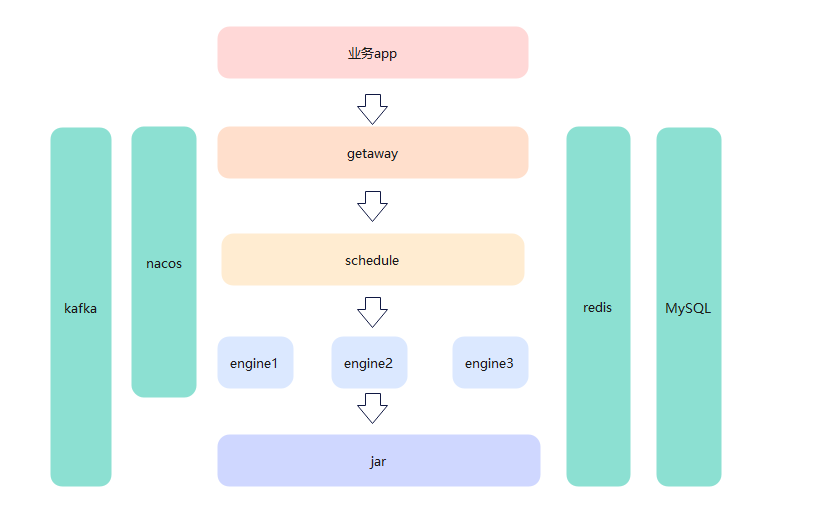
外部业务通过接口调用service服务,service服务内部通过配置文件调用封装好的jar包。kafka作为消息中间件,为service和运行的jar收集日志。
redis作为缓存中间件,为service和运行的jar提供缓存服务,而MySQL为为service和运行的jar提供持久化数据存储。
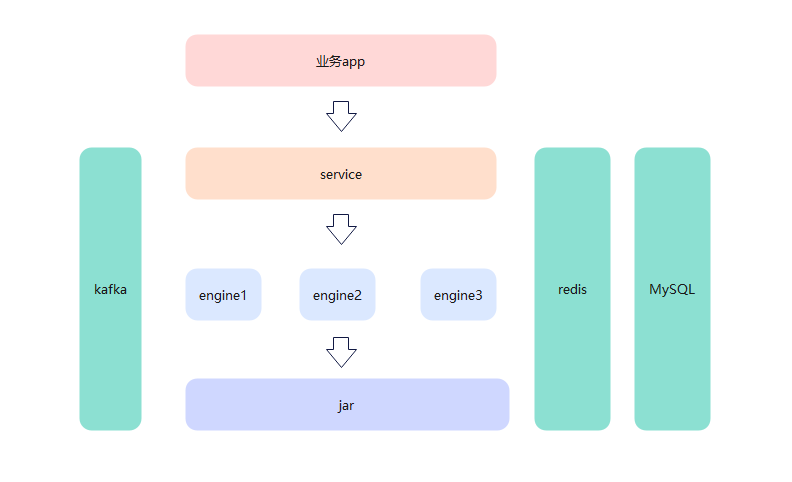
2、抽取engine服务
所有的逻辑都杂糅在service服务内,很明显不合适,如果需要扩展多节点的化,那整个service服务都要部署扩展。
其实扩展多节点,主要是为了可复用的jar包能在多节点运行,提高运行效率。
那么我们抽取出一个engine服务,只做加载运行jar包,这样扩展多节点的话,只要扩展engine服务就行。
在抽取完之后,engine和service就不是一个服务了,service调用engine可以通过http请求,但是engine还得向service返回心跳。最好的就是通过kafka来实现这个心跳检测。
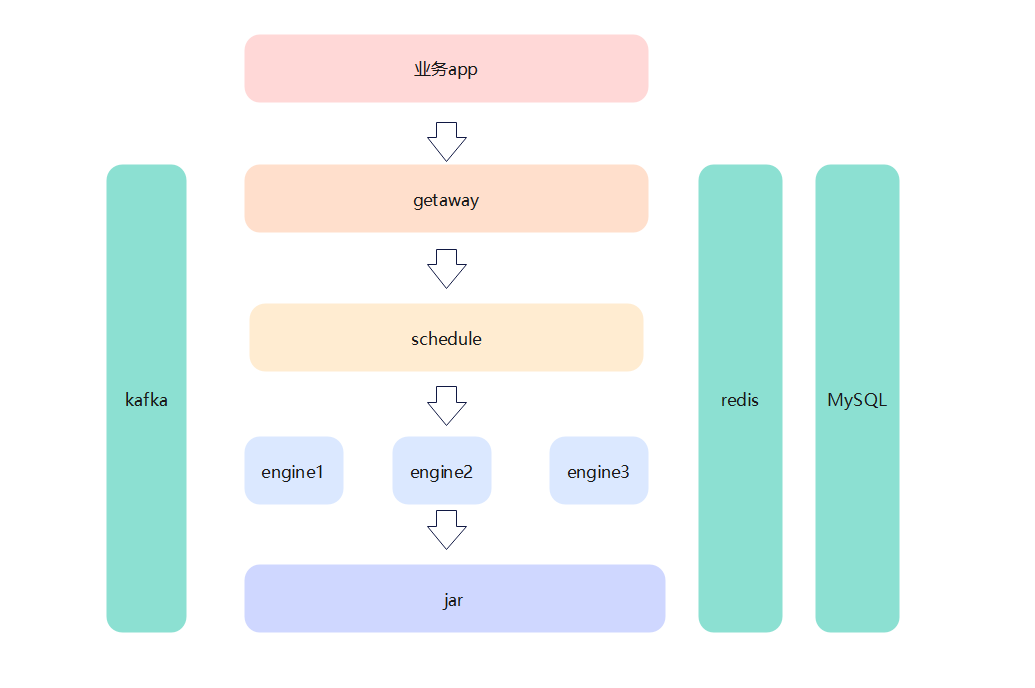
3、拆分service
为了提高可拓展性,我们抽出了engine服务,现在的service其实还负责两件事,第一个就是对外的接口暴露,第二个就是内部原子能力的调度。
现在为了使职责更内敛,我们将service再次拆分,拆分成:getaway和schedule
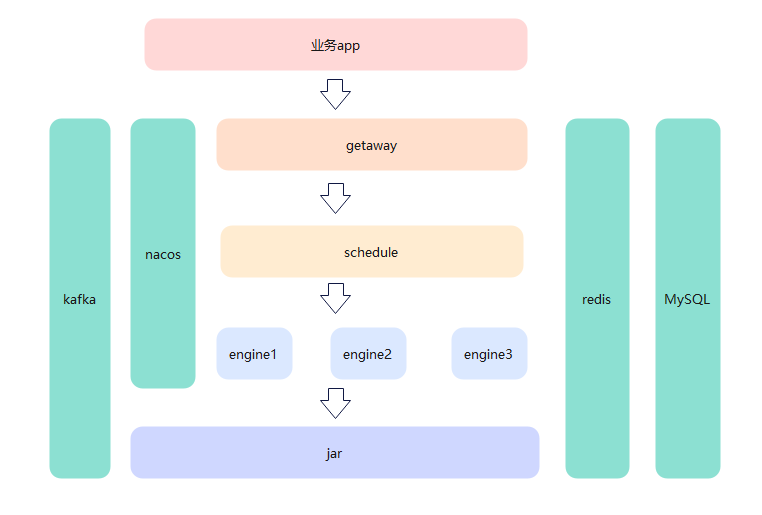
4、新增注册中心
现在又多了getaway和schedule服务,那么服务间的检测就不能只用kafka做的心跳检测了,得增加一个注册中心,这样都方便调度,尤其使engine有多节点部署的需求。engine和schedule都注册在nacos中,getaway和是schedule的调度都是先从nacos中获取相应的服务地址和端口,然后再开始调取相应接口。
5、调用链的转移
原本的调用链是在配置文件中的,经过service的拆分,现在应该在schedule的配置文件中。
虽然调用链是在开发中就已经配置好的,但是我们将调用链移动到MySQL中,这样可以更好的扩展。可以通过其他途径改动MySQL中的调用链,实现实时变更。
由于调用链这种配置不会随便改动,可以通过预加载,将其加载到redis中,这样可以减小MySQL的压力。