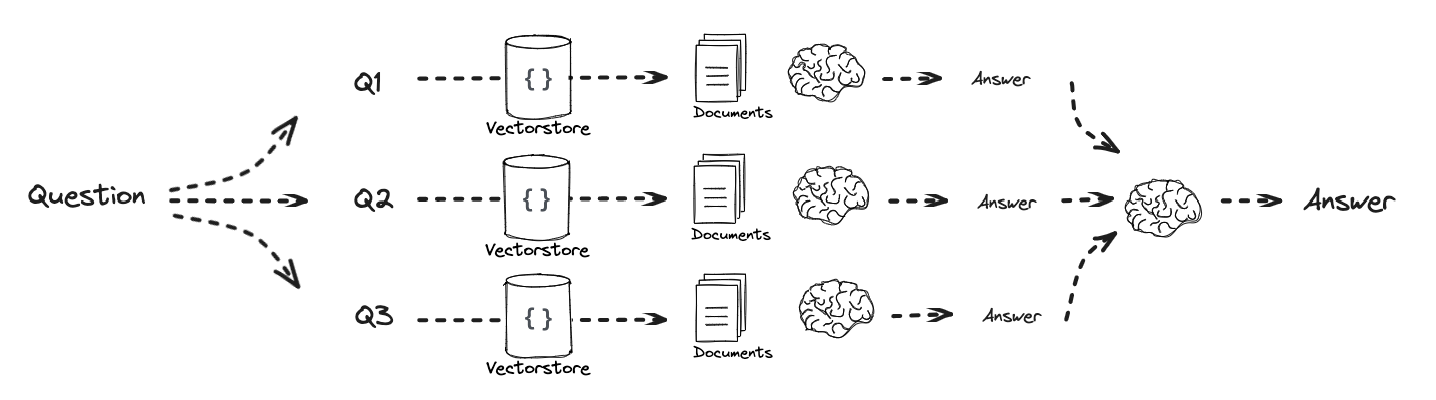
安装部署指南
开发过程均使用的Ubuntu,下面说明指南均基于Ubuntu使用。
中间件安装
需要安装 redis,mysql,minio,rabbitmq 自行搜索,服务器安装即可。
redis参考链接:https://cloud.tencent.com/developer/article/1639658
mysql参考链接:https://blog.csdn.net/xz2005/article/details/130145465
minio参考链接:https://www.cnblogs.com/hunttown/p/17358797.html
rabbitmq参考链接:https://www.cnblogs.com/hunttown/p/17352729.html
安装验证:redis和mysql可用本地连接工具可连接使用,minio和rabbitmq均有可视化界面,可在可视化界面登陆打开。
注意:注意服务器的端口有没有打开
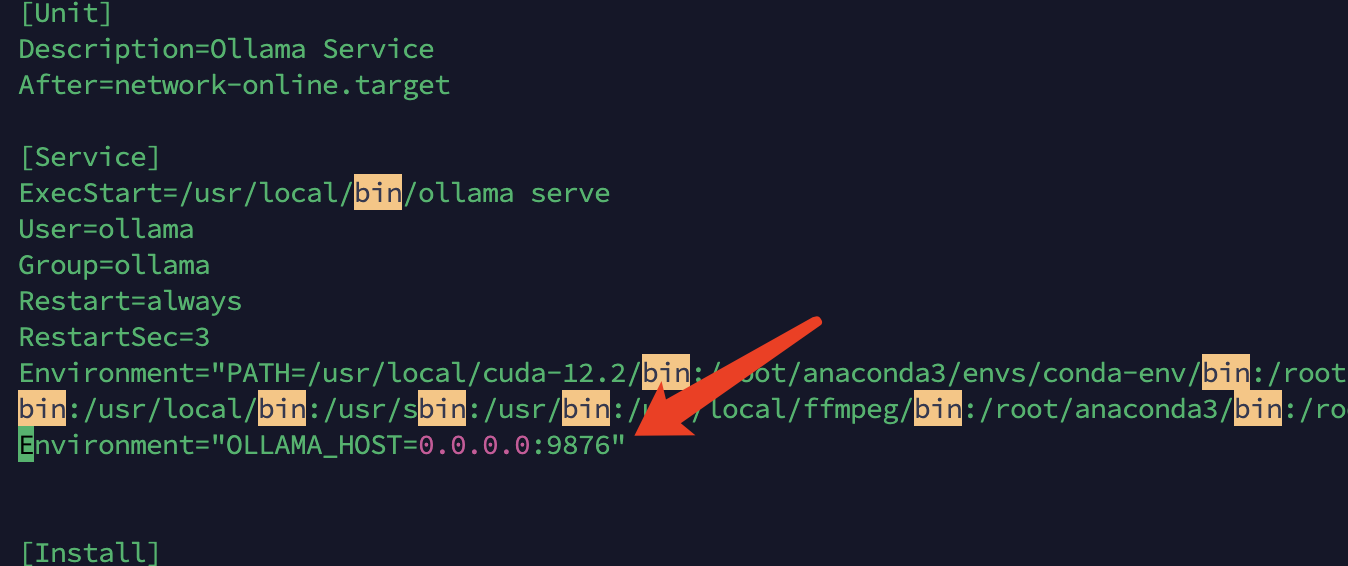
服务器43.154.80.35中已有安装好的中间件,可直接使用,账号密码,代码中的setting.py文件中都有,如果要修改成其他地址中间件,可直接在replace.py中修改相应字段,运行统一修改。
注:现在settings.py文件设置的是服务器43.154.80.35的内网ip,服务器账号密码和各中间件账号密码私信发送。
网络环境安装
服务器要求,
外网,ubuntu
安装软件
privoxy,tor,obfs4proxy
graph LR
a[代码]--8118端口-->b[privoxy]--9050端口-->c[tor]--网桥/obfs4proxy-->d[暗网]
代码
解压压缩包,网站目录下的setting文件中配置了代理端口,将请求发送到本级的8118端口
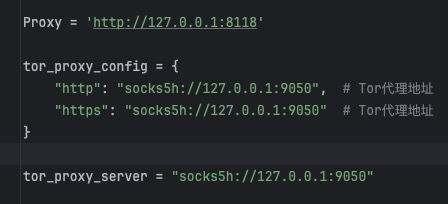
privoxy
1、安装:sudo apt-get install privoxy
2、修改配置文件:
进入配置文件 vim /etc/privoxy/config
修改接收代理:listen-address 127.0.0.1:8118
修改转发数据:最后一行添加 forward-socks5t / 127.0.0.1:9050 . (注意最后的点不能丢)
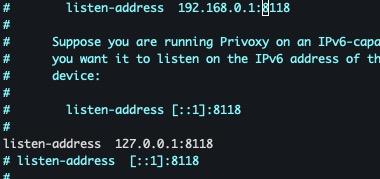

配置完重启使配置生效
tor
1、安装tor:sudo apt-get install tor
2、安装obfs4proxy: sudo apt-get install obfs4proxy
3、tor配置文件中添加网桥,vi /etc/tor/torrc,进行如图配置
查看tor 9050端口是否打开,若没有打开,去掉注释打开端口
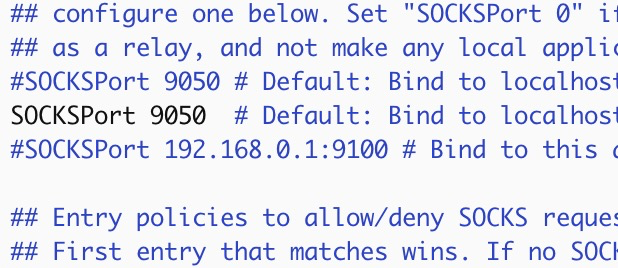
配置obfs4proxy
配置网桥,地址可用 obfs4 51.178.86.168:54874 773A7F4428AE519A892152EDA963477D85EE672A cert=xghcVpPhAAktkvVpYY6LDsE5iVayo4ADztSEwj0YcqGERxr3+v+RqScaOCC1O/uxeZinWA iat-mode=0,建议多申请几个做备用,网桥也会过期不可用

配置完重启使配置生效
验证网络通路
检测privoxy端口使用:netstat -an | grep 8118
检测tor端口使用:netstat -an | grep 9050
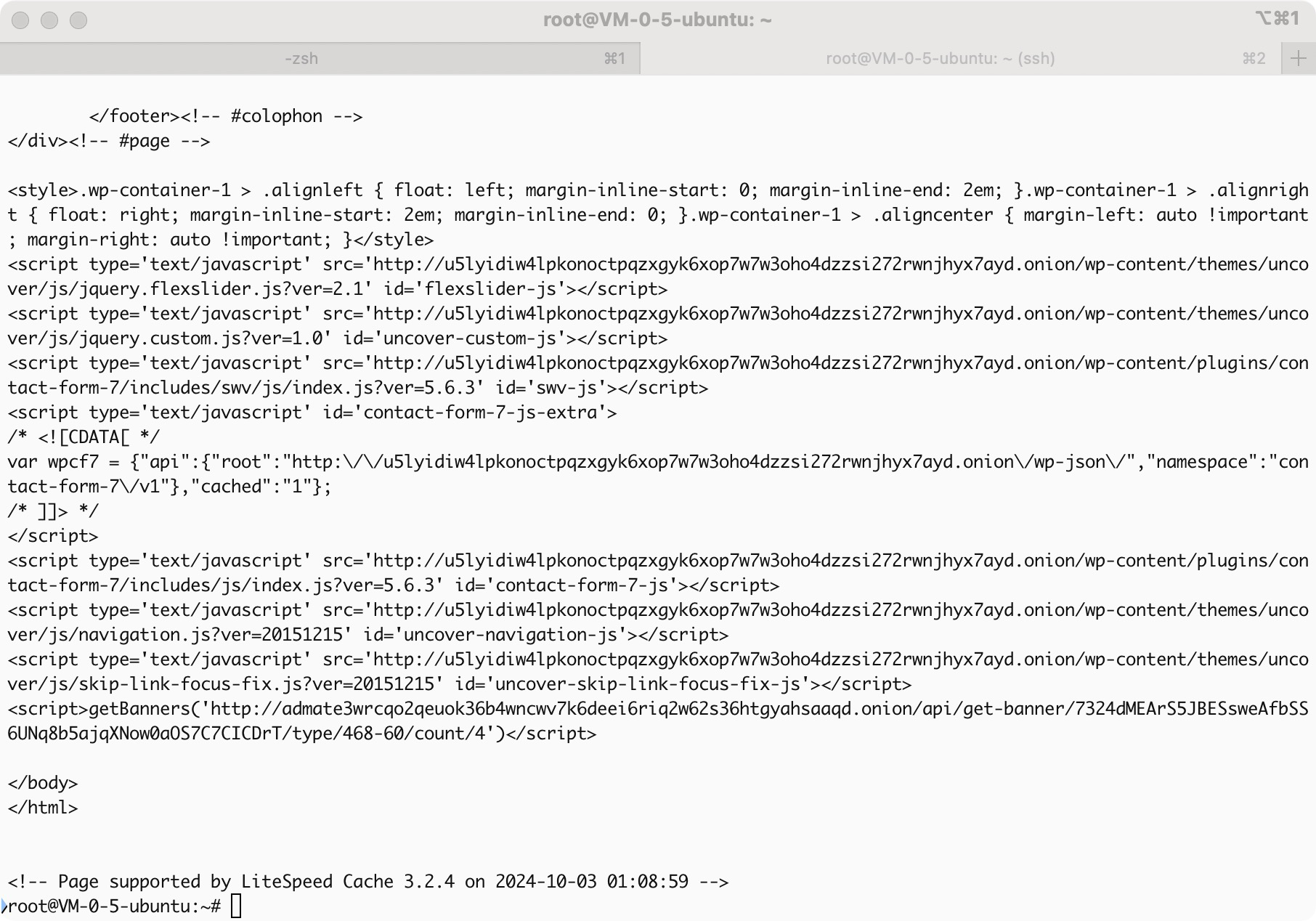
检测整个网络通路:curl -x http://127.0.0.1:8118 http://u5lyidiw4lpkonoctpqzxgyk6xop7w7w3oho4dzzsi272rwnjhyx7ayd.onion/
通路截图:
驱动安装
chrome和chromedriver安装
可借鉴:https://blog.csdn.net/weixin_44184990/article/details/123590435
Google-chrome:版本- Google Chrome 127.0.6533.88
Chromedriver:版本- ChromeDriver 127.0.6533.88
安装路径:/usr/bin/
虚拟环境安装
python环境:安装python,可参考https://blog.csdn.net/qq_45536969/article/details/130124934
虚拟环境:
安装虚拟环境:安装可参考https://blog.csdn.net/m0_64880493/article/details/132964831
安装依赖:安装requirements.txt文件中的所有依赖 pip install -r requirements.txt
代码运行
以下均以43.154.148.210服务器为例
1、打开虚拟环境,虚拟环境在 /opt/dwSpiders/dw-env/bin/下,命令:source /opt/dwSpiders/dw-env/bin/activate,各自安装的目录地址不一样,需要修改命中的路径,
2、进入网站目录,以torrez网站为例,命令:cd /opt/dwSpiders/torrez
3、添加修改cookie,43.154.80.35服务器上的redis中有示例,使用tor登陆后可按示例将cookie填写到自己的redis中(注:leakbase网站没有验证码,登陆逻辑已经写好,直接第4步运行即可)
4、启动代码:python3 run_torrez.py &
5、查看日志:如果当前窗口运行代码,则会自动弹出日志,如果不是,则进入网站目录下的logs目录,查看当前日期日志文件。
6、cookie过期:网站的cookie会过期,过期后直接在redis库中替换就行
7、如需要重跑,需要删除redis相应网站下dupefilter和bloom_fliter_img,这是url请求的指纹和图片的请求指纹,去重使用。
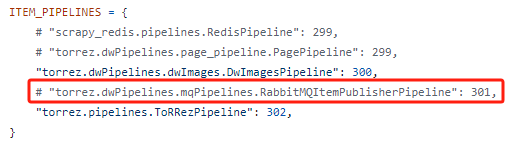
8、mq的使用,在每个网站目录下都加了mq的配置,如要使用,在setting文件中打开即可
9、不建议使用start.sh统一启动,可进入各自网站目录下单独启动运行,根据不同的服务器目录,start.sh需要配置不同的虚拟环境目录和代码目录
中间件初始化
mysql
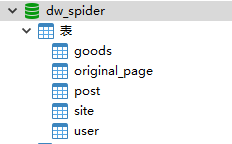
MySQL的初始化比较简单,在安装好的MySQL中安装 dw-spider 库,库中需要新建5张表(goods、original_page、post、site、user),如图。建表语句代码db目录下有。
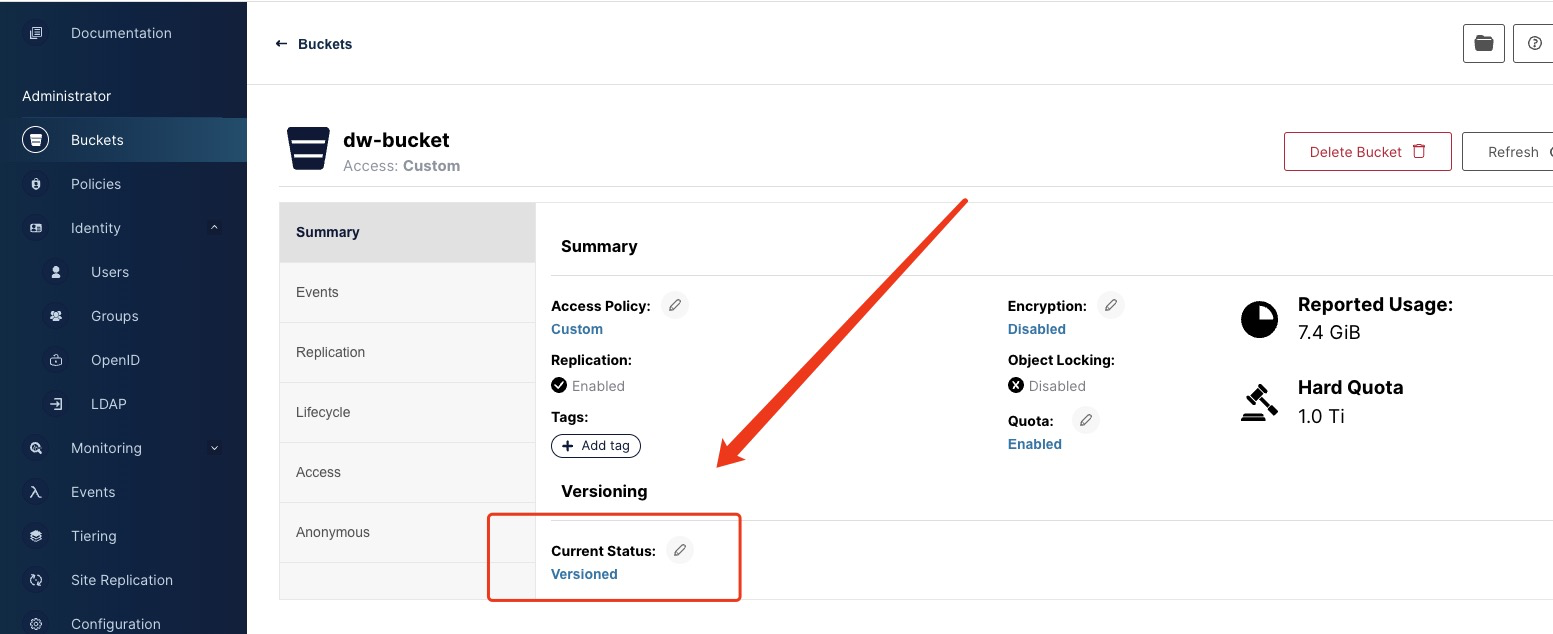
minio
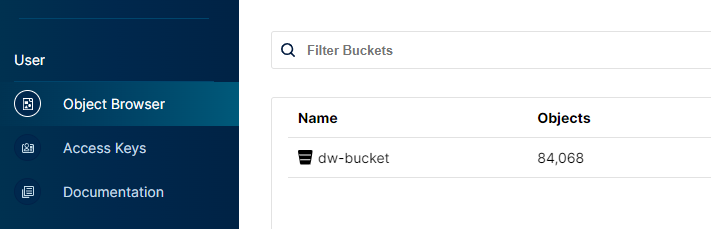
minio的初始化也比较简单,在其中新建dw-bucket,如图。
redis
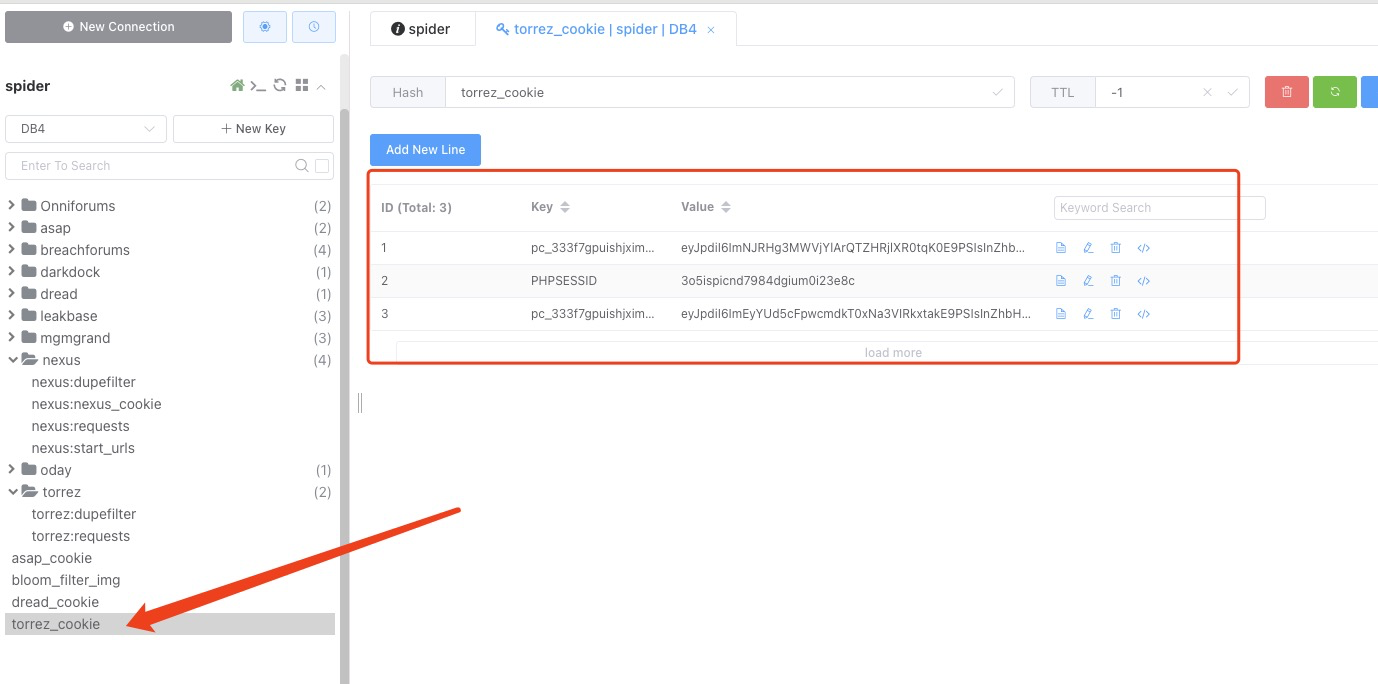
redis中需要预置8个网站的cookie:Onniforums、asap、breachforums、darkdock、dread、mgmgrand、nexus、torrez
redis的key为 网站名称:网站名称_cookie,示例:asap:asap_cookie
redis的value为 hash类型的键值对,如图
Onniforums: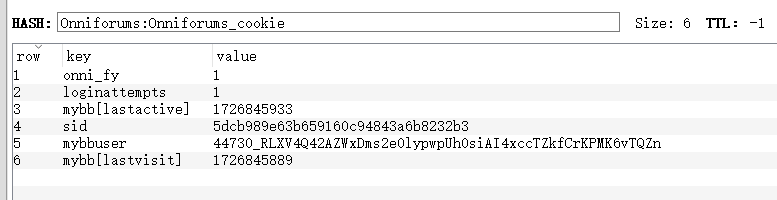
asap: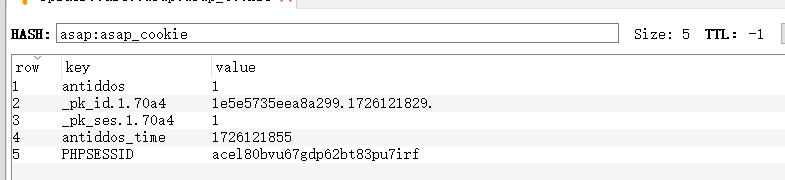
breachforums: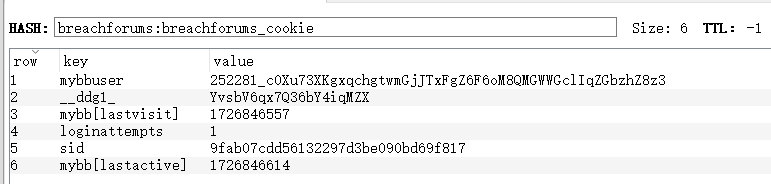
darkdock:
dread:
mgmgrand:
nexus:
torrez:
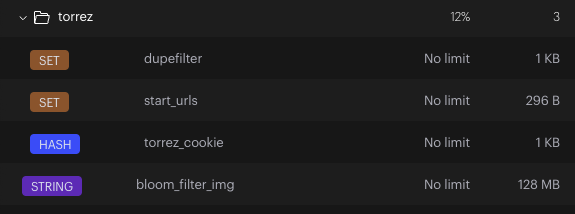
下图为代码运行后的redis截图,其中截了torrez网站和单独的bloom_filter_img。
bloom_filter_img:为所有图片请求过滤所用,内存放所有已请求的图片地址,其内存放的图片地址不会二次请求,如果重跑需删除,代码运行后会自行添加。
dupefilter:为站内地址请求过滤所有,内存放所有已请求的地址hash值,其内已存放的地址不会二次请求,如果重跑需要删除,代码运行后会自动添加。
start_urls:为代码运行时,起始请求的地址,重跑时需要删除,运行后会自动添加,起始地址请求后会自动删除。
torrez_cookie:为网站cookie,运行时需要添加,且保证cookie在有效期内。
rabbitmq
需要新建5个队列:goods、page、post、site、user。
可在可视化界面新建,如图。
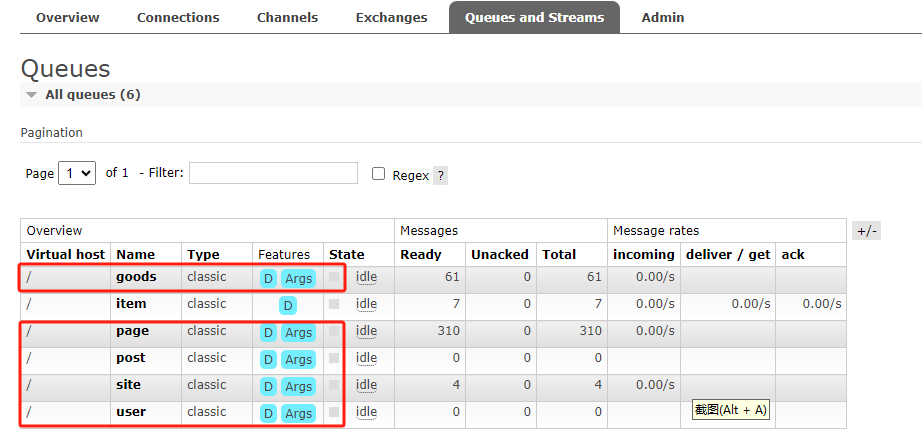
其初始交换机为scrapy,无需配置,代码运行时会自动配置。
注:每个队列都在每个网站的mqPipeline.py文件中绑定,不建议修改。
中间件配置修改
代码中有replace.py文件,运行次文件可统一修改当前文件夹下的setting.py文件中的中间件配置。replcae.py中的old_str字段为当前中间件配置,new_str字段为需要修改后的中间件配置,代码运行将setting文件中的old_str配置修改成new_str配置。