简述
这次面试场面有点大,6个面试官,但只有3个面试官提问了。前两个面试官回答的还行,后一个面试官直接问懵了。
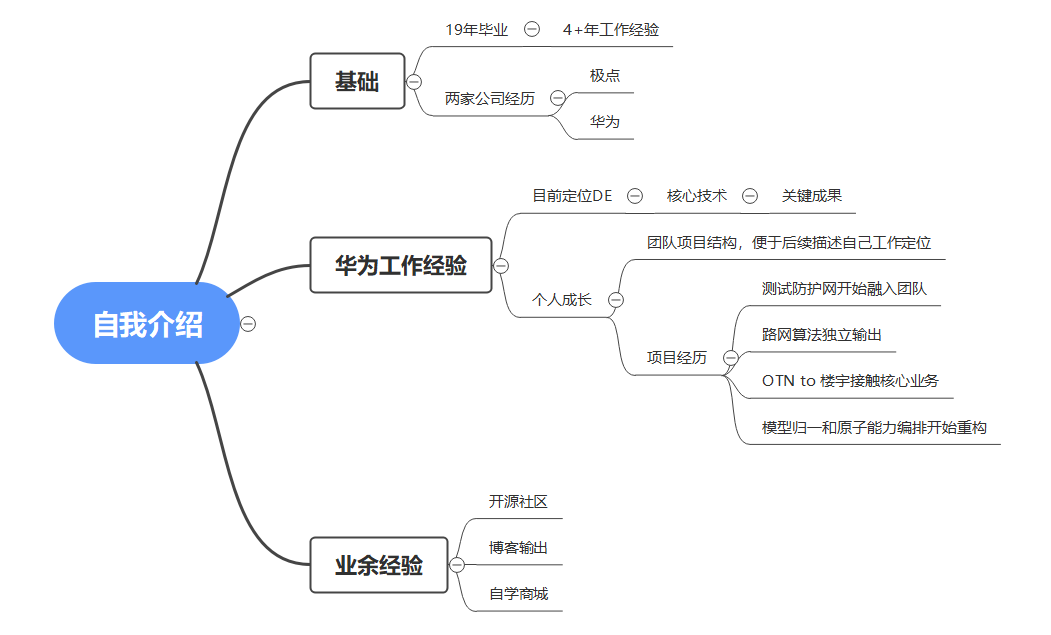
自我介绍
19年毕业,4年多工作经验,华为这边工作。
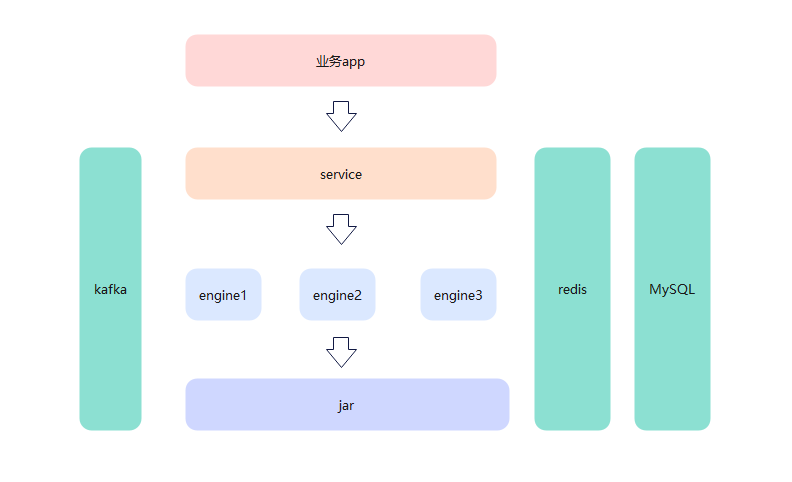
目前团队业务是以洞察、评估、规划和收益四个部分向运营商提供数字化机会点发现。
项目是以全球数据沙盘项目为基础,业务向外扩展OTN to 楼宇,OTN综合承载等项目。
自己近项目组以来,从构建测试网络开始了解全球数据沙盘项目,到路网算法开始参与项目,然后开始OTN to 楼宇参与业务拓展,到最后的模型收编和原子能力编排重构项目。
回溯
可以说一下自己参与开源项目dubbo,个人学习构建商城项目的框架代码,以及个人博客文章的分享。
也可以说一下自己在团队内的定位。
可以画个思维导图,下次按思维导图介绍。
第一个面试官
MySQL索引
问:简述一下mysql的索引
答:索引类似于书的目录,加快查找数据,它的存在空间换时间。空间就不用说了,索引的存在必然消耗空间,时间的话就是提高了查找效率,减少了消耗的时间。索引分为聚簇索引和非聚簇索引,以InnoDB而言,索引以B+数的形式存储,只不过聚簇和非聚簇在存储细节上有所不同。聚簇也就是主键索引,在叶子节点上是以主键和数据一起存放的,而非聚簇索引的叶子节点存储的是普通索引和主键。在查找数据的时候,如果是主键查询责直接通过B+数找到数据,非聚簇索引的话,要通过B+树先找到主键,在通过主键查到数据,这个过程叫做回表。为了提高查找的效率,所以我们一般在查询的时候尽量使用索引,且减少回表。
回溯
点应该都答到了,感觉面试官还比较满意回答,具体的细节和描述的方法可以更提高一点,显得更有条理性。
总述:索引类似于书的目录,空间换时间,占用了磁盘空间,减少了查找时间。
分述:分聚簇索引和非聚簇索引,二者在存储上的差异(B+树叶节点的不同),在查询上的差异(回表)。以及我们在实际使用的时候需要注意的点(减少回表,最左覆盖,索引下推,等)。
追问:既然说到B+树,说一下10个节点的红黑树需要查询一个节点的时间消耗
答:时间复杂度O(ln),红黑树的第一层是一个节点,第二层是2个节点,第三层是4个,第5层是8个。查询的话上来先比较根节点,如果比根节点大往右,否则往左…(简述了一下查询流程)…查询像二分查找,先找中间值,比大小等
回溯
应该是面试官想听到的,现场感觉面试官比较满意,但是自己不是很清楚红黑树,不清楚红黑树的非叶子节点是否保存了数据,还是和B+树一样只做比较。
增加实际业务中的的案例,走联合索引的案例,调换where中的条件顺序。
SpringMVC流程
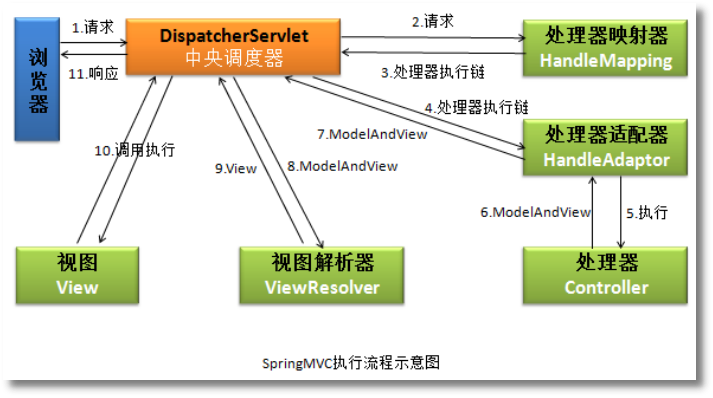
问:说一下MVC的查询流程
答:客户端 请求到 DispatcherServlet, DispatcherServlet到HandlerMapping,然后返回结果给DispatcherServlet,DispatcherServlet在将handler转发到适配器,适配器会有一些过滤拦截啥的,通过后到处理器,也就是controller->service->map,然后结果在原路返回到DispatcherServlet,DispatcherServlet在拿到结果后回去调用视图解析器啥的,去将返回的结果解析渲染。
回溯
回答面试官比较满意,听其语义主要想听到DispatcherServlet,但是此流程中记得是在适配器中会有拦截过滤,不是特别确定,已经返回结果后的视图解析渲染,两个组件名称记得不是特别清楚。
服务间通信
问:你们有多模块多服务吗,服务间的调用是用的什么。
答:有,上面自我介绍中也说到了,我们所有业务基本可以分为:洞察,评估,规划,收益,四个模块。模块间的调用用的是http请求。
追问:请求的结果是要转换的,你们是怎么转换的。
答:我们的请求不涉及到请求结果的转换,不是那种强依赖。我们模块间的数据交互都是放在数据库的,比如洞察处理完的数据会放在数据库,然后调用评估的模块开始处理,评估模块处理的时候会调用数据库的数据处理,处理的结果会放回数据库,而不是返回给评估模块,这样更解耦。
回溯
其实对这请求调用的方式记得不是特别清楚了,需要复习回顾一下。
https://blog.csdn.net/Andy19891117/article/details/134981402
RPC调用和http调用,RPC基于传输层TCP协议,Http基于应用层http协议,所以RPC调用的传输效率更高。Http规定了返回的格式而RPC没有。
第二个面试官
jar包加载
问:简历中说的到的原子能力编排是怎么理解的,包是spring jar还是啥,编排是怎么理解。
答:jar包是fast jar,不是那种有启动类的可执行jar包,编排的话,是我们把能力抽取成一个个的jar包,再以可视化配置的方式,类似于链式调用。
追问:编排的结果,jar包的顺序执行,这个是以什么数据结构存储的。
答:存在数据库中,是以字符串的形式存储的,在读取到数据库中字符串,在以特定的字符将字符串分割开,然后遍历执行。
追问:前端是怎么配置调用后端的jar的
答:我们是按迭代内的业务需求配置上线的,前台只是提供一个可视化的界面供开发配置,其实我们更习惯直接在配置文件xml中配置,配置完的xml文件会提交到代码仓,在我们的部署阶段,会将这配置文件解析成字符串保存在数据库中,供读取。
追问:这个项目里的调度和引擎服务怎么理解。
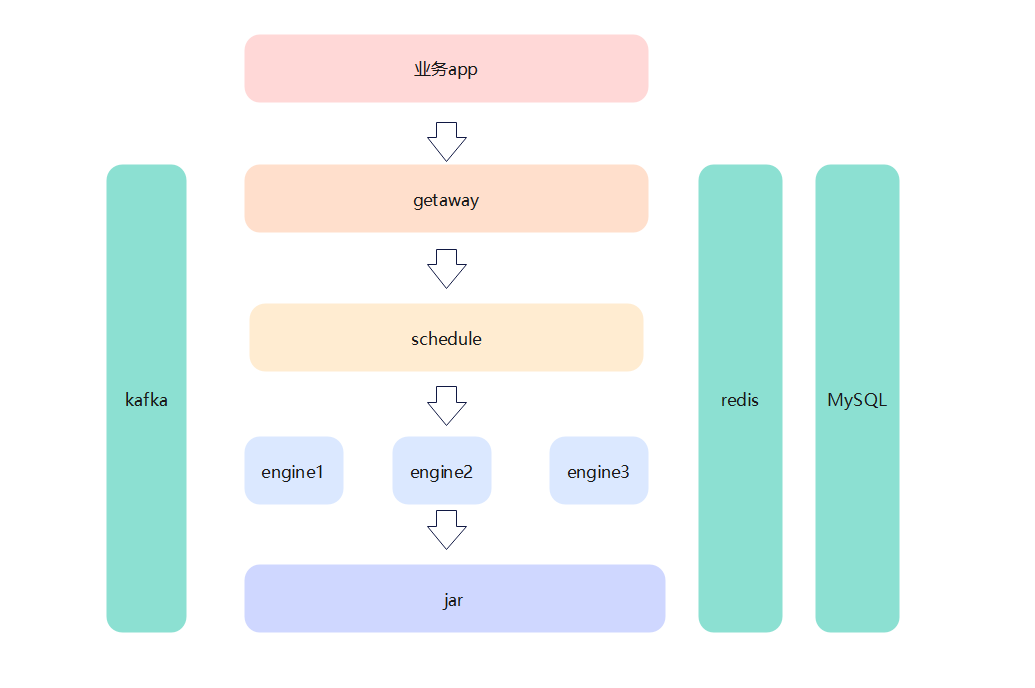
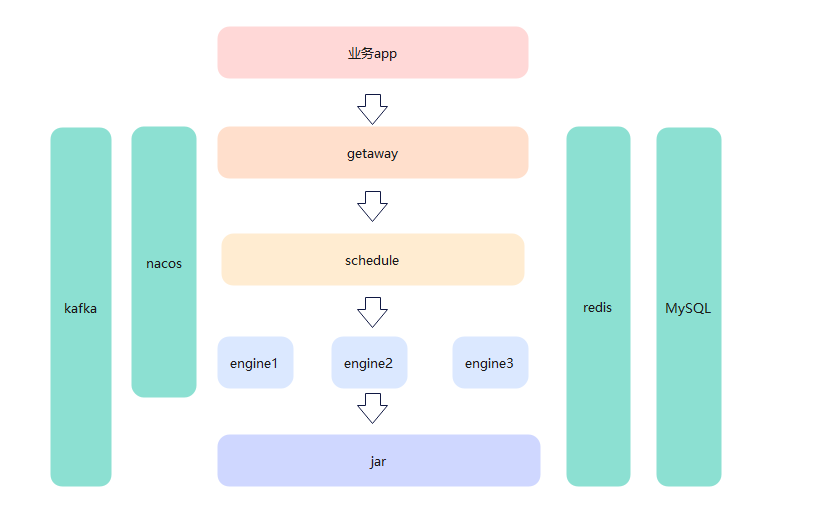
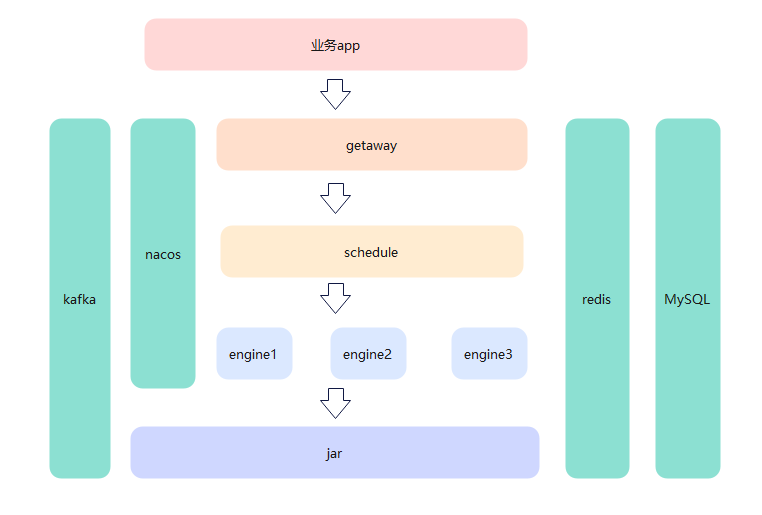
答:这个网关,调度,引擎内容都比较简单,网关的话直接对外,调度只负责调用原子能力jar,引擎是加载运行jar。这么分是为了职责更单一内敛。
追问:jar包是怎么加载的。
答:读取到lib目录下的依赖,先将依赖通过双亲依赖加载给加载进来,然后在通过同一规范的jar包入口,开始调用jar内的方法。
追问:双亲加载有三个加载器,加载器是啥。
答:记得不是特别清了,只记得一个是系统加载,两个是加载外部文件依赖加载。
回溯
面试感觉一般,虽然大部分都答到了,但是还有结果点不熟。
1、jar包的分类不熟
fat jar
2、jar包的加载,了解大概流程,不了解其具体细节。
3、三个父加载器忘了,没想起来名字。
4、怎么卸载jar包
启动类加载器(Bootstrap Class Loader):也称为根类加载器,它负责加载Java虚拟机的核心类库,如java.lang.Object等。启动类加载器是虚拟机实现的一部分,它通常是由本地代码实现的,不是Java类。
扩展类加载器(Extension Class Loader):它是用来加载Java扩展类库的类加载器。扩展类库包括javax和java.util等包,它们位于jre/lib/ext目录下。
应用程序类加载器(Application Class Loader):也称为系统类加载器,它负责加载应用程序的类。它会搜索应用程序的类路径(包括用户定义的类路径和系统类路径),并加载类文件。
注解加载
问:注解是怎么加载的
答:看过源码,记得不是特别清了,spring启动类上会有enable开启注解加载,后面通过一层层的调用,大概3~4层,读取到lib目录下的文件,然后再通过条件判断是否加载。
回溯
回答一般,之前确实看过,现在确实忘了
自动配置原理:SpringBoot 项目的核心注解 @SpringBootApplication,这个注解位于启动类上方。@SpringBootApplication 看作是 @Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。自动装配核心功能的实现是通过@EnableAutoConfiguration内部的AutoConfigurationImportSelector类。AutoConfigurationImportSelector 类实现了 ImportSelector 接口,也就实现了这个接口中的 selectImports 方法,该方法主要用于获取所有符合条件的类的全限定类名,需要为这些类创建对象并加载到 IoC 容器中。@ConditionOnXXX 中的所有条件都满足,该类才会生效
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制。
@Configuration:允许在上下文中注册额外的 bean 或导入其他配置类,作用与 applicationContext.xml 的功能相同。
@ComponentScan: 扫描包下的类中添加了@Component (@Service,@Controller,@Repostory,@RestController)注解的类 ,并添加的到spring的容器中,可以自定义不扫描某些 bean。

getAutoConfigurationEntry:
第 1 步:判断自动装配开关是否打开。默认 spring.boot.enableautoconfiguration = true,可在 application.properties 或 application.yml 中设置
第 2 步:用于获取 EnableAutoConfiguration 注解中的 exclude 和 excludeName。
第 3 步:从 META-INF/spring.factories 读取需要自动装配的所有配置类。
第 4 步:这一步有经历了一遍筛选过滤,@ConditionOnXXX 中的所有条件都满足,该类才会生效
https://blog.csdn.net/m0_59749089/article/details/131280769
第三个面试官
bean加载
问:如果我想再bean初始化时候改变其变量值,或者说再方法前打印一个日志。
答:使用代理,再调用方法前后打印日志。
追问:不是代理,是在初始化的时候。
答:在xml文件中,配置修改,在bean初始化的时候给其赋值。
回溯
貌似这也不是面试官想要的,确实不知道是啥,得查资料研究看看。
bean的加载过程:
加载bean信息–>实例化bean–>属性填充–>初始化阶段–>后置处理
https://blog.csdn.net/m0_46897923/article/details/129850717
容器化
问:你们容器化用的怎么样。
答:我们部门目前才开始推,我们还没有开始使用容器化,但是自己也搭环境简单使用过容器化,比如部署一个redis、mysql等。
回溯
熟悉了解一下容器化,这方面得了解确实不够,只是简单得使用了一下。
多线程
问:核心线程数10,最大线程数20,现有1w个并发,为什么线程数一直是10,不是队列里有1w。
答:不知,尝试分析,是不是资源不够,没办法新增。
回溯
确实不知,等了解。
问:synchronized的用法
答:修饰代码块或者方法,注意synchronized()中括号内的内容,可以是变量,对象和class类,对应锁的颗粒不一样。
追问:对象和class类有什么不一样。
答:对象是可以重复new的,但是class类只有一个,跟静态变量一样,用的时候要注意,别用错导致没锁好。
追问:线程的睡眠和唤醒是怎么样的。
答:A、B两个线程,A运行到某个地方,停住了睡眠了,B开始运行,运行到某个地方,通过A的方法唤醒A。
回溯
1、感觉追问的对象和类有什么不一样,没回答到他想要的,复习一下。
2、睡眠唤醒的模型有点忘了,再代码实操一下。
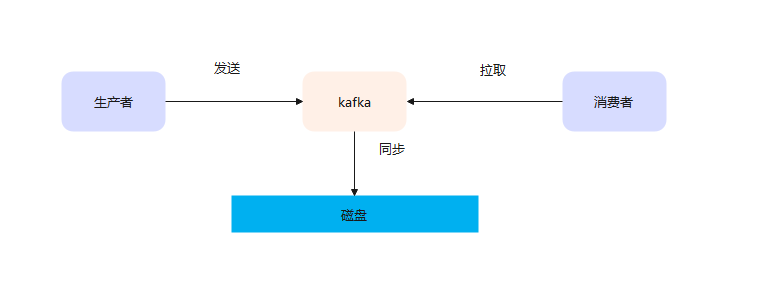
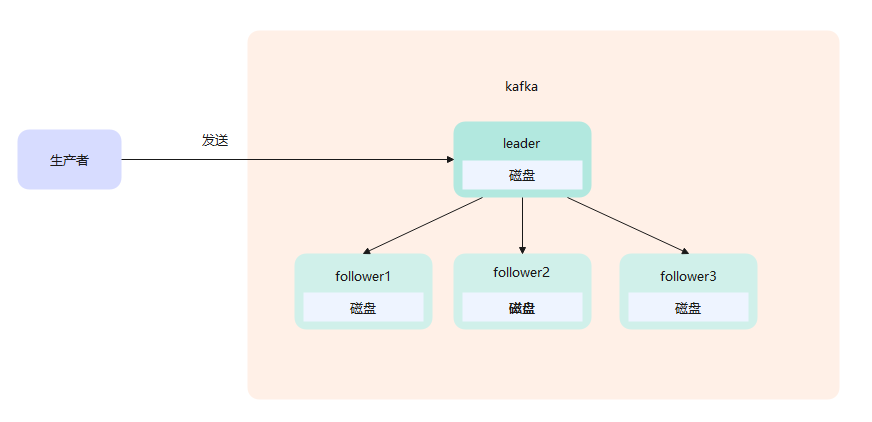
kafka
问:kafka里的消费者组是什么。
答:消费者的集合,一堆消费者组成的一个集合。
问:topic里的分区能被消费者组内的多个消费者消费吗
答:不能,一个分区只能被消费者组内一个消费者消费。
问:怎么保证生产者生产的消息,顺序消费。
答:都放在一个分区内,kafka不保证topic内的消息是顺序的,但是保证分区内的数据是顺序消费的。
问:消息是怎么划分分区的。
答:根据key的计算,具体的计算方法不知道。
问:如果key为null会怎么样。
答:不知
回溯
1、消费者组的概念
2、分区和消费者组、消费者的消费关系模型
3、分区的指定逻辑。
4、key为null会怎样。
随机选取一个分区缓存发送,过了分区的缓存时间后在随机选取一个分区缓存发送。
https://blog.csdn.net/yizhiniu_xuyw/article/details/109206709







 总结
总结