REST
RESTful本身是一种风格而不是规范,本文为该风格的规范实现的最佳实践,本文档详细说明了HTTP RESTful API的定义和使用规范,作为接口调用者和实现者的重要参考。
接口风格
遵循RESTful设计风格,同时控制复杂度及易于使用,仅遵循大部分原则。 遵循原则:
- 使用https协议
- 版本号放入URL或Header
- 只提供json返回格式
- post,put上使用json作为输入
- 使用http状态码作为错误提示
- Path(路径)尽量使用名词,不使用动词,把每个URL看成一个资源
- 使用HTTP动词(GET,POST,PUT,DELETE)作为action操作URL资源
- 过滤信息
- limit:指定返回记录数量
- offset:记录开始位置
- direction:请求数据的方向,取值prev-上一页数据;next-下一页数据
- page:第几页
- per_page:每页条数
- total_count:总记录数
- total_pages:总页数,等于page时,表示当前是最后一页
- sort:column1,column2排序字段
- orderby:排序规则,desc或asc
- q:搜索关键字(uri encode之后的)
- 返回结果
- GET:返回资源对象
- POST:返回新生成的资源对象
- PUT:返回完整的资源对象
- DELETE:返回一个空文档
- 速率限制
- X-RateLimit-Limit: 每个IP每个时间窗口最大请求数
- X-RateLimit-Remaining: 当前时间窗口剩余请求数
- X-RateLimit-Reset: 下次更新时间窗口的时间(UNIX时间戳),达到下个时间窗口时,Remaining恢复为Limit
未遵循原则:
- Hypermedia API(HATEOAS),通过接口URL获取接口地址及帮助文档地址信息
- 限制返回值的域,fields=id,subject,customer_name
- 缓存,使用ETag和Last-Modified
参考:
模块和版本说明
接口模块相互对立且有版本管理,模块名作为APP配置项进行存储,每个模块的版本号version和endpoint在应用初始化时调用api模块信息接口(通过传递客户端应用名称和版本号获取各个API模块的endpoint和version)获取并存储。
模块模块用途最新版本号account帐户v1sms短信v1open一些开放接口,不需要公共参数v1
公共参数
公共请求参数是指每个接口都可能需要传递的参数,公共参数通过header传递。
参数是否必须说明及header格式app所有接口必须请求客户端应用标识,取值*-ios、*-android、*-pc、*-h5
header格式:
X-Co-App: $appuser_idApp登录后所有接口都传,
Web通过session机制获取用户标识
header格式:
Authorization: CoAPI base64(user_id:token)tokenApp登录后所有接口都传,
Web通过session机制获取授权访问令牌
header格式:
Authorization: CoAPI base64(user_id:token)
- Web应用通过cookies传递session id,user_id和token无需传递,接口会从session自动获取;
- 同一token值在App和Web各应用间通用(token即为session id);
- APP修改user-agent,在原有user-agent的尾部添加
$app/$version和NetType/$value。如:
Dalvik/2.1.0 (Linux; U; Android 6.0.1; MI 4LTE MIUI/V7.5.3.0.MXGCNDE) $app-android/3.0.0 NetType/4GMozilla/5.0 (iPhone; CPU iPhone OS 10_3_2 like Mac OS X) AppleWebKit/603.2.4 (KHTML, like Gecko) $app-ios/3.0.0 NetType/WIFI
- app取值及释义示例
app取值客户端名称【域名】admin-pc管理中心PC网页版【admin.url.com】admin-h5管理中心手机网页版【admin.url.com】admin-ios管理中心iOS版admin-android管理中心Android版
Cookies
- 用于告知服务端是否支持Webp的Cookie:cookie name是
supportWebp,取值是1(支持)和0(不支持),未传递时服务端默认取值为0。
- Webview植入Session的Cookie:
JWT & OAuth2
- Json Web Token可用于替代session-cookie机制。但会存在一些问题,比如为过期token强制失效问题(用户修改了密码后,无法强制其他的终端token全部失效)。
- OAuth2是授权其他开发者访问自己应用有限权限的授权机制。
权限
- 权限分为
none:无需任何授权;token:需要用户登录授权,可通过header Authorization和Cookie CoSID传递;admintoken:需要管理员登录授权,可通过header Authorization和Cookie CoCPSID传递;token || admintoken:用户登录授权或管理员登录授权都可以;
sign:需要签名,一般用于服务端内部相互调用。
状态码说明
正确
接口正常访问情况下,服务器返回2××的HTTP状态码。
HTTP状态码200 OK - 表示已在响应中发出、资源更改成功(GET、PUT)201 Created - 新资源被创建(POST)204 No Content - 资源被删除(DELETE)
错误
当用户访问接口出错时,服务器会返回给一个合适的4××或者5××的HTTP状态码;以及一个application/json格式的消息体,消息体中包含错误码code和错误说明message。
- 5××错误(
500=<status code)为服务器或程序出错,客户端只需要提示“服务异常,请稍后重试”即可,该类错误不在每个接口中列出。
- 4××错误(
400=<status code<500)为客户端的请求错误,需要根据具体的code做相应的提示和逻辑处理,message仅供开发时参考,不建议作为用户提示。
- 部分错误示例:
codemessageHTTP状态码InvalidToken未登录或授权过期,请登录401 UnauthorizedValidationError输入字段验证出错,缺少字段或字段格式有误422 Unprocessable EntityAccountNotExist账户名不存在404 Not FoundInvalidPassword密码错误401 UnauthorizedNotFound请求的资源不存在404 Not FoundAccountHasExist账户名已经存在409 ConflictMobileHasBinded手机号已经绑定其他账户409 ConflictInvalidSign参数签名验证未通过403 ForbiddenInvalidSMSCode短信验证码错误403 ForbiddenExpiredSMSCode过期的短信验证码403 ForbiddenFrequencyLimit发送过于频繁,请稍后再试403 ForbiddenTimesExceeded达到最大发送次数限制,请明天再试403 ForbiddenVerifyTimesExceeded达到最大校验次数,请明天再试403 ForbiddenRateLimitExceeded接口调用次数超过限制,请稍后再试429 Too Many Requests InternalError服务异常,请稍后再试500 Internal Server Error
参数传递
遵循RESTful规范,使用了GET, POST, PUT, DELETE共4种请求方法。
- GET:请求资源,返回资源对象
- POST:新建资源,返回新生成的资源对象
- PUT:新建/更新资源,返回完整的资源对象
- DELETE:删除资源,返回body为空
- GET请求不允许有body, 所有参数通过拼接在URL之后传递,所有的请求参数都要进行遵循RFC 3986的URL Encode。
- DELETE删除单个资源时,资源标识通过path传递,批量删除时,通过在body中传递JSON。
- POST, PUT请求,所有参数通过JSON传递,可选的请求参数,只传有值的,无值的不要传递,contentType为application/json。
4种请求动作中,GET、PUT、DELETE是幂等的;只有POST是非幂等的。幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。 是非幂等是判断接口使用POST还是PUT的决定条件
注意: APP端获取json数据时,对于数值类型字段必须以数值类型转换,无论传递过来的值是否带引号。
速率限制Rate Limiting
- 为了防止API被恶意调用,对API调用进行速率限制。
- 速率限制为每IP每15分钟5000次(dev/qa为10W)调用(15分钟是一个时间窗口)。
- 限制是针对所有接口模块一起计算的(Redis key为
APIRL:{IP}),暂时没有特殊的模块或单个接口(未来可能有)。
- 你可以通过每个接口返回的HTTP headers了解当前速率限制的情况:
- X-RateLimit-Limit: 每个IP每个时间窗口最大请求数
- X-RateLimit-Remaining: 当前时间窗口剩余请求数
- X-RateLimit-Reset: 下次更新时间窗口的时间(UNIX时间戳),达到下个时间窗口时,Remaining恢复为Limit
- 超出速率限制,返回以下错误
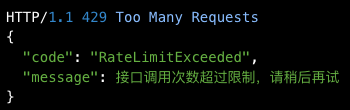
安全注意事项
- 用户登录后用户的token;aliyun OSS的bucket、AccessKey ID与AccessKey secret;微视频的appid、sign、bucket;这些关键数据通过调用接口获得,需要在客户端以安全的方式存储。
- 音频视频在APP内的存储,不允许被拷贝(即使越狱或root后拿走也无法使用)。
测试工具
推荐Chrome浏览器插件Postman作为接口测试工具, Postman下载地址

文档生成工具
调用示例
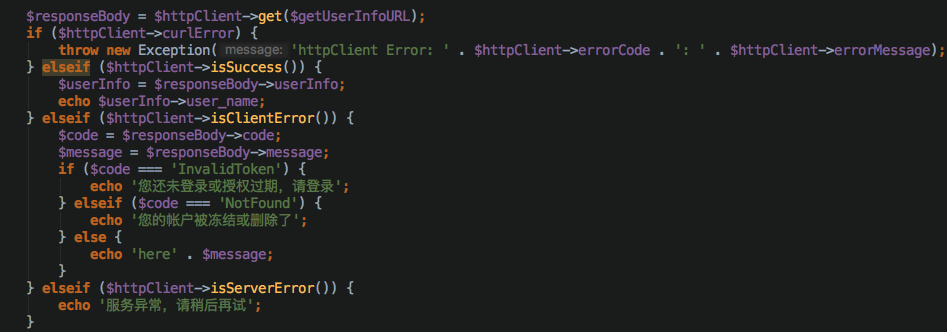
- 伪代码

- PHP
API模块信息获取
- App配置文件中仅存储api模块名,App初始化时请求获取api模块信息,获取各个api模块的信息(endpoint和version)。